参考文献不是来源本身
许多研究人员认为他们已经验证了来源,但实际上他们只验证了引文串。这是一个严重的错误。引文可能看起来完整、一致且符合学术规范,但仍然指向错误的论文、混合记录或根本没有原始来源。

引文与来源并非一回事。
这听起来显而易见,但许多研究工作流程却悄悄地将它们视为可以互换的。
引文是对来源的描述。
来源是实际的论文、记录或原始文献,你应该能够追溯、检查和验证它们。
一旦这两者混淆不清,工作流程就会在早期阶段做出错误的判断。

这就是反复出现的错误。
有人看到一个参考文献,其中包含:
- 作者姓名
- 出版年份
- 期刊名称
- DOI
然后他们认为:“很好,来源就在那里。”
不一定。
那里可能只是一个看起来足够完整、足以通过的引文形式的字符串。
这与拥有一个经过验证的来源不是一回事。
许多研究人员认为他们正在检查来源,但他们实际上只检查了记录的薄薄一层。
有时他们会验证:
- DOI是否指向一个真实的页面。
- 作者姓名是否拼写正确。
- 期刊名称是否正确。
- 出版年份是否正确。
这些检查并非毫无用处,但它们还不够。
它们本身都无法回答真正的问题:
这个引文能否追溯到一个真实、原始的来源记录,并且该记录的所有细节都与引文匹配?
这才是重要的标准。
AI让这个问题变得更糟,因为它生成的参考文献在尚未得到证实之前就常常给人一种完整的感觉。
这才是真正的风险。
参考文献不必明显荒谬才能具有危险性。在许多情况下,它之所以危险,恰恰是因为它看起来很正常。
标题可能很接近。
作者列表可能看起来合理。
期刊名称可能听起来正确。
DOI甚至可能指向一篇真实的论文,但不是同一篇。
这就是一个薄弱的引文如何在工作流程中畅通无阻的原因。

真正的失败点通常不是格式问题。
而是来源替换。
工作流程始于一个来源声明,但被检查的只是该声明周围的引文外壳。
这导致了以下问题:
- 引文指向一篇真实的论文,但它与引文所支持的论点无关。
- 引文指向一篇真实的论文,但它与引文所支持的论点相矛盾。
- 引文指向一篇真实的论文,但它与引文所支持的论点只有微弱的联系。
- 引文指向一篇真实的论文,但它只是一个摘要,而不是原始研究。
- 引文指向一篇真实的论文,但它已被撤回。
此时,论点开始依赖于比表面看起来更薄弱的基础。
一个更强大的工作流程将引文验证视为来源验证,而不是字符串验证。
这意味着要按正确的顺序提问。
首先:原始来源记录在哪里?
其次:标题、作者、年份、出版地点和DOI是否都与该记录匹配?
第三:如果另一位研究人员遵循此引文,他们是否能在不猜测的情况下找到相同的来源?
如果答案在任何一点上中断,那么来源层仍然不稳定。
如果来源层不稳定,那么草稿就比看起来更薄弱。
这里有一个简单的测试,它能发现比人们预期更多的问题。
随便找一个引文,然后问:
- 这个引文是否指向一个真实的、可追溯的来源?
- 这个来源是否与引文所支持的论点完全匹配?
- 如果有人遵循这个引文,他们是否会找到完全相同的来源,并且该来源支持引文所声称的内容?
这个习惯将标准引向正确的方向。
它将工作流程从“看起来不错”转向“值得信赖”。
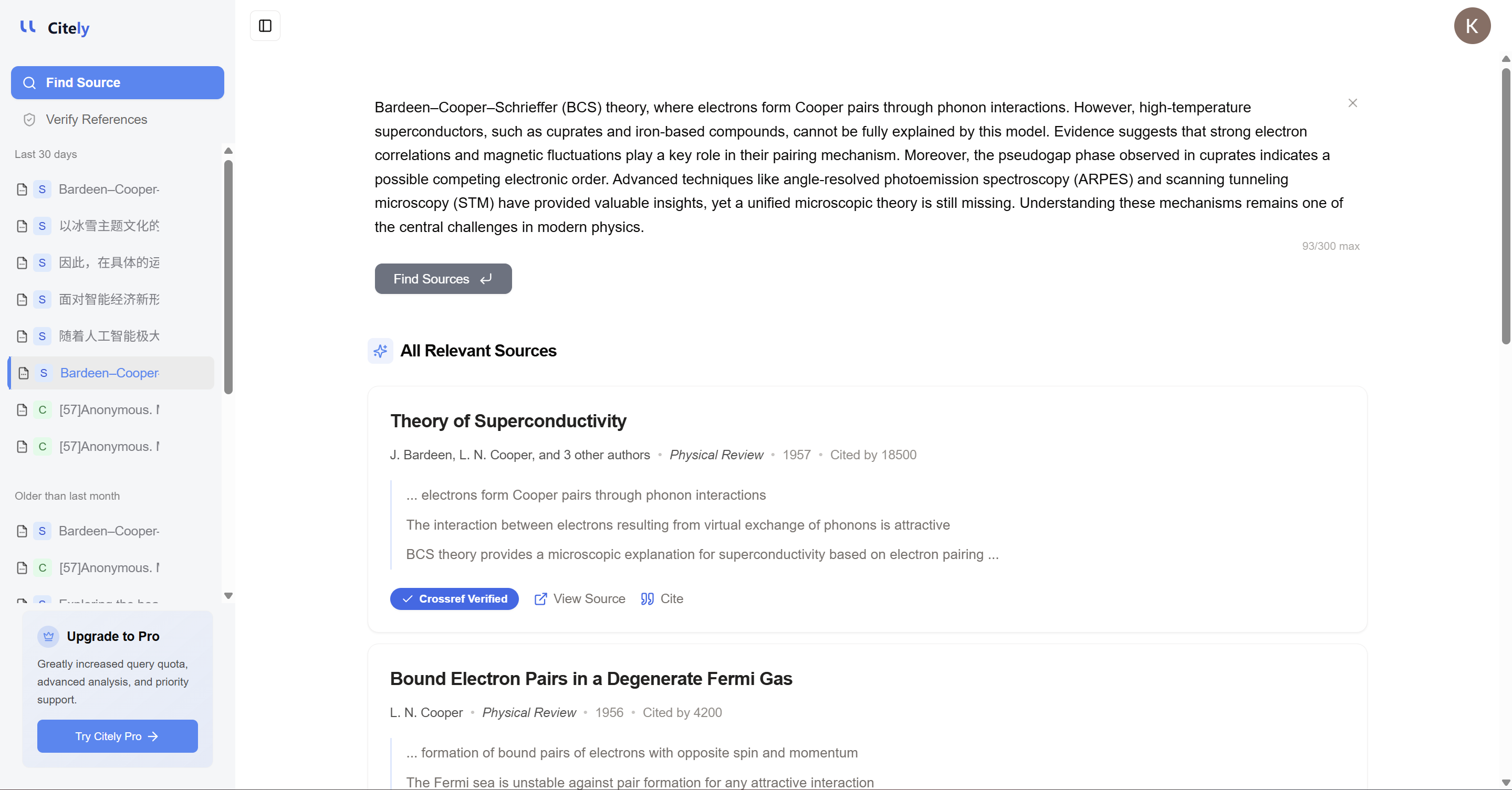
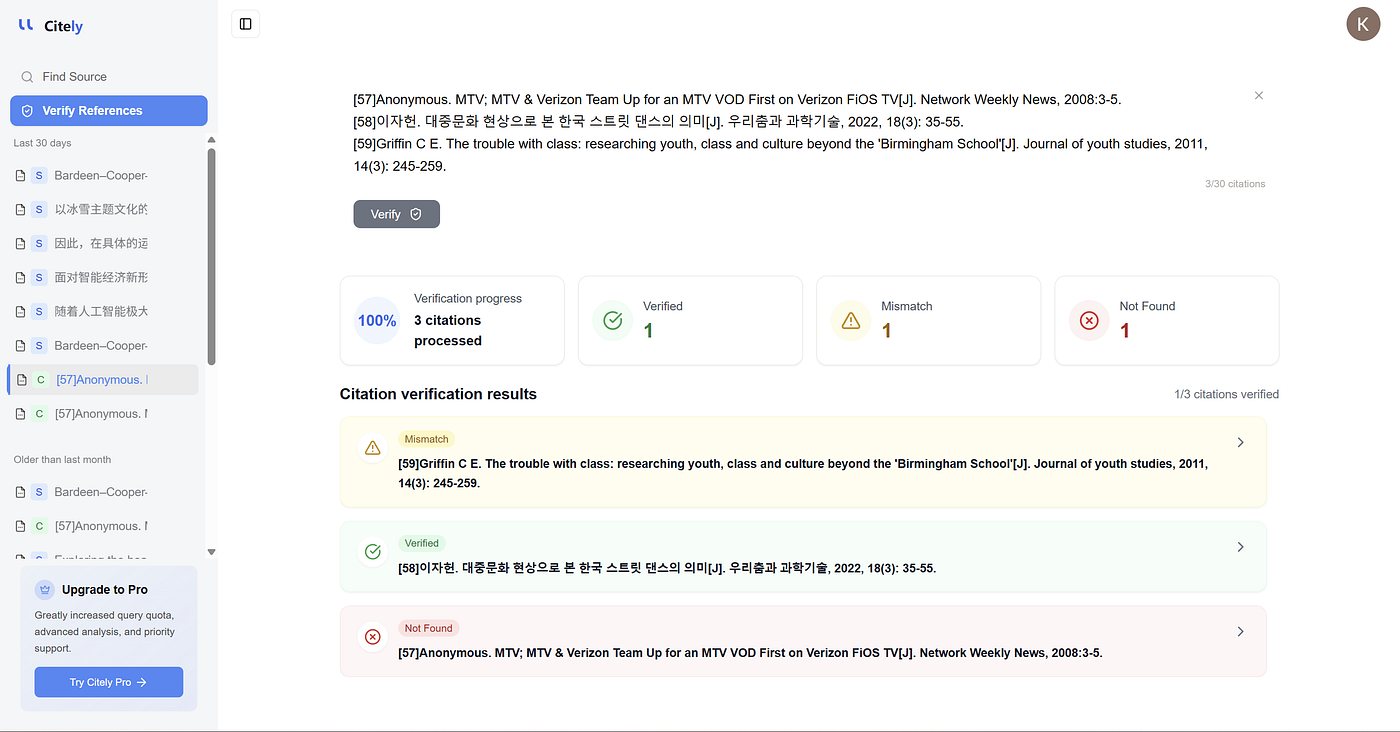
这正是 Citely 的用武之地。
问题不仅在于研究人员需要帮助管理参考文献。更深层次的问题是,他们常常需要帮助检查引文是否真的对应一个真实的来源,追溯原始记录,并在引文层面的错误演变为证据层面的问题之前将其捕获。
这就是为什么这种区别如此重要。
如果引文没有被追溯到来源,那么工作流程就停止得太早了。
引文不是来源本身。
如果你的工作流程将这两者视为相同,那么它最终会信任那些实际上未经核实的参考文献。
这种错误不总是看起来很严重。
但它却悄悄地削弱了整篇论文的严谨性。
相关文章
继续阅读你关心的主题。
无法追溯的引文,就不是证据
引文格式再正确,如果无法追溯到真实原始来源,它就无法作为证据。在AI辅助研究中,这个问题尤为突出,因为看似可信的参考文献可能在未经核实前就已传播开来。
阅读更多从文本中查找引文:如何找到段落背后的原始来源
学习如何使用 Google Scholar、Crossref 和 AI 驱动的来源查找器工作流程,从句子、段落或研究主张中找到原始来源。
阅读更多引用检查器与引用生成器:有何不同?
引用生成器创建格式化的参考文献。引用检查器验证参考文献是否真实准确。本文将解释这两种工具的功能以及何时使用它们。
阅读更多AI引用检查工具对比:2026年,哪些工具能真正识别虚假参考文献?
并非所有引用检查工具功能都相同。有些修正格式,有些检查抄袭。只有少数工具能验证您的参考文献是否真实存在。本文将详细介绍每种工具的功能和局限性。
阅读更多2026年如何判断来源可信度:实用框架
CRAAP测试是为AI时代之前设计的。本文提供了一个2026年评估来源可信度的更新框架,包括数字验证技术和自动化工具。
阅读更多引用核查101:CrossRef、DOI以及如何识别虚假引用
CrossRef收录了超过1.5亿篇学术著作的元数据。了解DOI的工作原理、CrossRef如何通过验证识别虚假引用,以及如何利用这些系统清理任何参考文献列表。
阅读更多