La citation n'est pas la source
De nombreux chercheurs pensent avoir vérifié une source alors qu'ils n'ont vérifié qu'une chaîne de citation. C'est une grave erreur. Une citation peut sembler complète et académique tout en pointant vers le mauvais document ou aucune source.

Une citation n'est pas la même chose qu'une source.
Cela semble évident, mais de nombreux flux de travail de recherche les traitent discrètement comme s'ils étaient interchangeables.
Une citation est une description d'une source.
Une source est le document, l'enregistrement ou le document original que vous devriez pouvoir retrouver, inspecter et vérifier.
Dès que ces deux éléments sont confondus, le flux de travail commence à prendre de mauvaises décisions très tôt.

C'est l'erreur qui ne cesse de se manifester.
Quelqu'un voit une référence qui contient :
- Un titre
- Des auteurs
- Une année
- Un journal
- Un DOI
Et ils pensent : « Bien, la source est là. »
Pas nécessairement.
Ce qui est là peut n'être qu'une chaîne de caractères en forme de citation qui semble suffisamment aboutie pour passer.
Ce n'est pas la même chose qu'avoir une source vérifiée.
De nombreux chercheurs pensent qu'ils vérifient la source, mais ils ne vérifient en réalité qu'une fine couche de l'enregistrement.
Parfois, ils vérifient :
- Si la référence est formatée selon les règles APA, MLA, Chicago, BibTeX ou Vancouver.
- Si le DOI est présent.
- Si le DOI est valide.
- Si le DOI pointe vers un document.
- Si le document existe sur Google Scholar, PubMed, arXiv ou OpenAlex.
- Si le document est dans leur gestionnaire de références (Zotero, Mendeley, EndNote).
Ces vérifications ne sont pas inutiles, mais elles ne sont pas suffisantes.
Aucune d'entre elles, à elle seule, ne répond à la vraie question :
Cette citation peut-elle être retracée jusqu'à un enregistrement de source original et réel qui correspond à tous ses détails ?
C'est la norme qui compte.
L'IA aggrave ce problème car elle génère des références qui semblent souvent complètes avant d'être fondées.
C'est le vrai risque.
La référence n'a pas besoin d'être manifestement absurde pour être dangereuse. Dans de nombreux cas, elle devient dangereuse précisément parce qu'elle semble normale.
Le titre peut être proche.
La liste des auteurs peut être plausible.
Le nom du journal peut sembler correct.
Le DOI peut même pointer vers un vrai document, mais pas le même.
C'est ainsi qu'une citation faible passe à travers le flux de travail sans friction.

Le véritable point de défaillance n'est généralement pas le formatage.
C'est la substitution de source.
Le flux de travail commence par une affirmation de source, mais ce qui est vérifié n'est que l'enveloppe de la citation autour de cette affirmation.
Cela conduit à des problèmes tels que :
- La citation pointe vers un document différent de celui que l'auteur a réellement utilisé.
- La citation est un mélange de deux documents différents.
- La citation est une hallucination complète de l'IA.
- La citation est un document rétracté ou une source non fiable (par exemple, un article de blog déguisé en article de journal).
À ce stade, l'argument commence à s'appuyer sur quelque chose de plus faible qu'il n'y paraît.
Un flux de travail plus robuste traite la vérification des citations comme une vérification des sources, et non comme une vérification des chaînes de caractères.
Cela signifie poser les questions dans le bon ordre.
Premièrement : où est l'enregistrement de la source originale ?
Deuxièmement : le titre, les auteurs, l'année, le lieu de publication et le DOI correspondent-ils tous à ce même enregistrement ?
Troisièmement : si un autre chercheur suivait cette citation, arriverait-il à la même source sans deviner ?
Si la réponse échoue à un moment donné, la couche source est toujours instable.
Et si la couche source est instable, le brouillon est plus faible qu'il n'y paraît.
Voici un test simple qui détecte plus de problèmes que les gens ne s'y attendent.
Prenez n'importe quelle citation et demandez :
- Si je cliquais sur cette citation, est-ce que j'arriverais au document original ?
- Si je cliquais sur cette citation, est-ce que j'arriverais au document original que l'auteur a réellement utilisé ?
- Si je cliquais sur cette citation, est-ce que j'arriverais au document original que l'auteur a réellement utilisé et qui correspond à tous les détails de la citation ?
Cette habitude déplace la norme dans la bonne direction.
Elle éloigne le flux de travail de « ça a l'air bien » pour le rapprocher de « on peut faire confiance ».
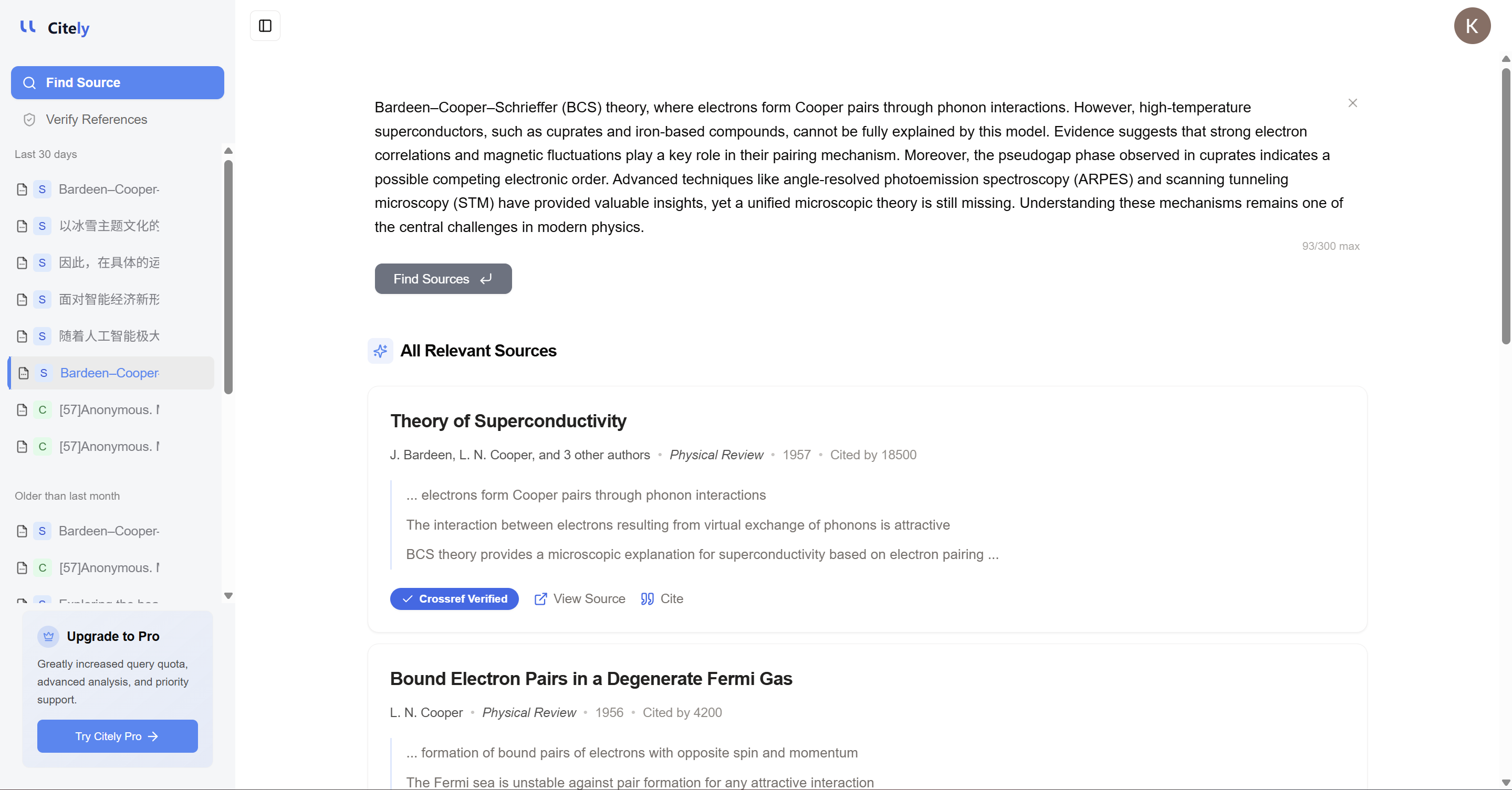
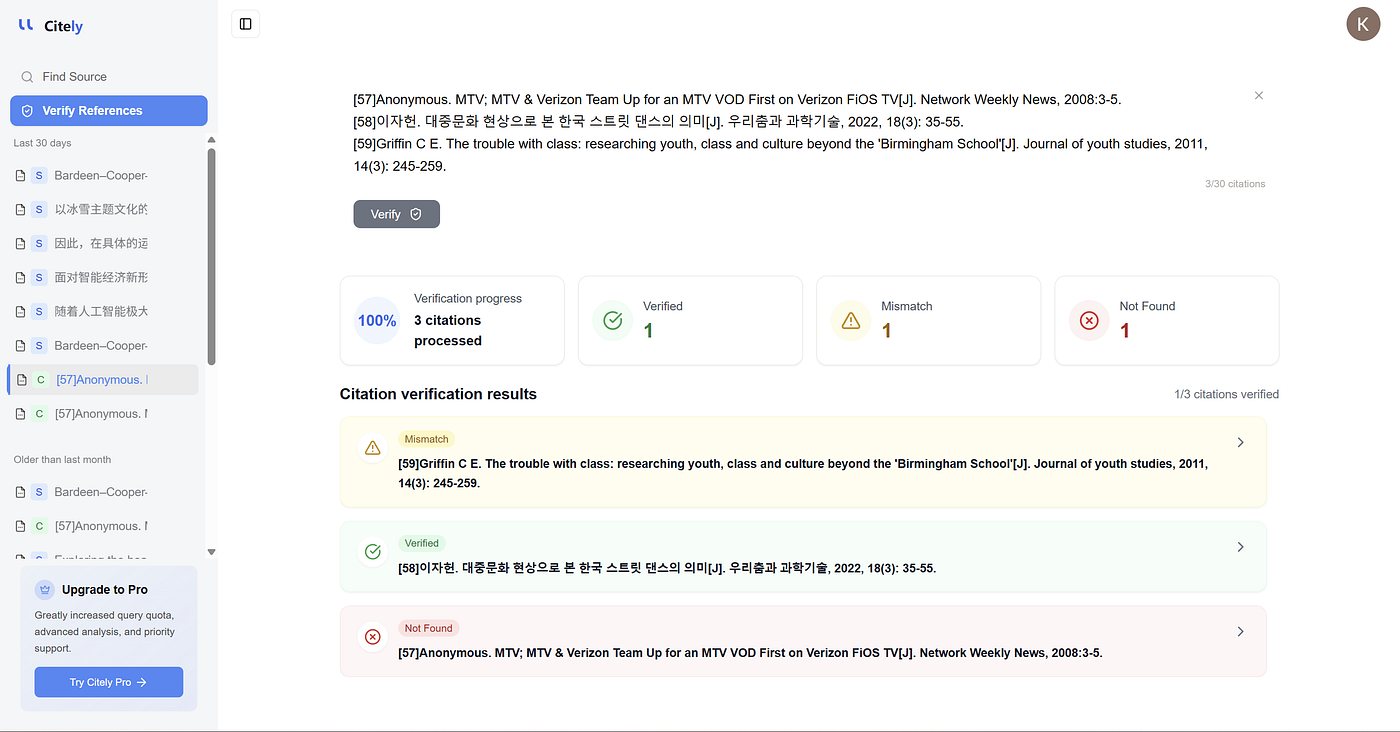
C'est exactement là que Citely s'intègre naturellement.
Le problème n'est pas seulement que les chercheurs ont besoin d'aide pour gérer les références. Le problème plus profond est qu'ils ont souvent besoin d'aide pour vérifier si une citation correspond réellement à une source réelle, pour retrouver l'enregistrement original et pour détecter les erreurs au niveau des citations avant que ces erreurs ne deviennent des problèmes au niveau des preuves.
C'est pourquoi cette distinction est si importante.
Si une citation n'est pas retracée jusqu'à une source, alors le flux de travail s'arrête trop tôt.
La citation n'est pas la source.
Et si votre flux de travail traite ces deux choses comme identiques, il finira par faire confiance à des références qu'il n'a pas réellement vérifiées.
C'est le genre d'erreur qui ne semble pas toujours dramatique.
Mais elle affaiblit discrètement l'ensemble du document.
Articles connexes
Continuez à explorer les sujets qui vous intéressent.
Une citation intraçable n'est pas une preuve
Une citation peut être correctement formatée et pourtant échouer au test le plus important : la traçabilité. Si un lecteur ne peut pas la retracer jusqu'à une source originale réelle, elle ne fonctionne pas comme preuve. Dans les flux de travail de recherche assistés par l'IA, ce problème est plus important que jamais.
Lire la suiteComparaison des vérificateurs de citations IA : Qu'est-ce qui détecte réellement les fausses références en 2026 ?
Tous les vérificateurs de citations ne font pas la même chose. Certains corrigent le formatage. D'autres vérifient le plagiat. Seuls quelques-uns vérifient si vos références existent réellement. Voici ce que chaque type fait — et ne fait pas.
Lire la suiteComment vérifier la crédibilité d'une source : Un cadre pratique pour 2026
Le test CRAAP a été conçu pour un monde sans IA. Voici un cadre actualisé pour évaluer la crédibilité des sources en 2026, incluant des techniques de vérification numérique et des outils qui automatisent le processus.
Lire la suiteVérification des citations 101 : CrossRef, DOI et comment débusquer les fausses références
CrossRef contient les métadonnées de plus de 150 millions d'œuvres savantes. Découvrez le fonctionnement des DOI, comment la vérification CrossRef détecte les fausses citations et comment utiliser ces systèmes pour nettoyer toute liste de références.
Lire la suiteOutils de recherche de sources : fonctionnement et choix (2026)
Les outils de recherche de sources parcourent les bases de données académiques pour trouver des articles correspondant à votre sujet. Découvrez leurs différences avec Google Scholar, les bases de données qu'ils interrogent et l'outil adapté à votre flux de travail.
Lire la suiteComment trouver la source originale de n'importe quel texte en ligne (2026)
Quelqu'un a partagé une affirmation, une citation ou une statistique sans source ? Voici 5 méthodes pour retrouver la source originale de n'importe quel texte, de la recherche par phrase exacte à la recherche de sources assistée par IA.
Lire la suite