AIによる引用の幻覚:その実態、発生理由、そして防止策
AIツールは、本物のように見える偽の学術参考文献を生成します。このガイドでは、引用の幻覚の3つのタイプを説明し、それらを検出する方法、そして実用的な防止ワークフローを提供します。
大規模言語モデルが引用を生成する際、それはデータベースを検索しているわけではありません。トレーニングデータ内のパターンに基づいて、引用がどのように見えるべきかを予測しているのです。その結果、完璧な書式規則に従ったテキスト(もっともらしい著者名、実在する雑誌名、正しく構造化されたDOI)が、存在しない論文に付随して生成されます。
これが引用の幻覚であり、今日の学術論文執筆において最も急速に増加している誠実性リスクです。
引用の幻覚とは?
引用の幻覚は、AIツールが正当に見える参考文献を生成するものの、それが実際の出版物に対応していない場合に発生します。この「幻覚」という用語は、より広範なAI研究コミュニティから来ており、流暢で自信に満ちているが事実とは異なるあらゆる出力を指します。
学術参考文献の文脈では、幻覚は特に危険です。なぜなら、その出力が実際の引用の形式や慣習を密接に模倣しているからです。経験豊富な研究者でさえ、幻覚の引用を見ても、一見したところ何も問題がないように見えることがあります。
幻覚引用の3つのタイプ
すべての偽の引用が同じように作られているわけではありません。そのバリエーションを理解することで、何に注意すべきか、そしてどの検出方法が各タイプに有効かを知ることができます。
タイプ1:完全に捏造された参考文献
引用全体が創作されています。タイトル、著者、雑誌、年、DOIのいずれも実際の出版物に対応していません。これは最も検出が容易なタイプです。CrossRef、PubMed、またはGoogle Scholarで検索しても結果はゼロです。
例: "Zhang, W., & Roberts, T. (2024). Adaptive neural frameworks for multilingual sentiment analysis. Journal of Computational Linguistics, 48(3), 112-128."
これは完璧に見えます。しかし、このタイトルの論文は存在しません。雑誌は存在しますが、第48巻第3号にはこの記事は含まれていません。著者は実在する研究者ですが、共著したことはありません。
タイプ2:キメラ参考文献
AIが異なる論文からの実在する要素を組み合わせて、架空の引用を生成します。著者名は実在し、引用された雑誌に論文を発表しています。雑誌と巻も実在します。しかし、特定の論文(その著者、そのタイトル、その号)は存在しません。
このタイプは、部分的な検証が成功するため危険です。著者が実在することを確認できます。雑誌が実在することを確認できます。著者がその雑誌に論文を発表していることさえ見つけられるかもしれません。しかし、特定の論文は架空のものです。
タイプ3:歪められた参考文献
実際の論文は存在しますが、AIが1つ以上の詳細を間違えています。出版年が1年ずれていたり、共著者の名前がスペルミスされていたり、DOIの数字が入れ替わっていたりします。参考文献は実際の出版物にほぼ一致しているため、体系的な検証なしでは最も検出が難しいタイプです。
AIツールが引用を幻覚する理由
大規模言語モデルは論文のデータベースを持っていません。彼らは何も「検索」しません。彼らは統計的パターンに基づいてシーケンス内の次のトークンを生成します。
あるトピックに関する引用を求めると、モデルは「[トピック]に関する引用」のパターンに一致するテキストを生成します。それは以下に基づいています:
- そのトピックに関連するトレーニングデータに頻繁に登場する著者名
- その分野に関連する雑誌名
- もっともらしい範囲内の年
- 標準的なプレフィックス/サフィックス構造に従うDOI形式
各要素は統計的にもっともらしいものです。しかし、それぞれが独立して生成されるため、その組み合わせはしばしば架空のものとなります。
これは、検索エンジンが間違った結果を返すのとは根本的に異なります。検索エンジンは実際のドキュメントを取得し、それらを誤ってランク付けする可能性があります。LLMは、存在しなかったドキュメントを生成します。
問題の発生頻度は?
研究によって異なりますが、コンセンサスは憂慮すべきものです:
- GPT-4は、明示的な検索ツールなしで学術参考文献を求められた場合、約25〜35%のケースで捏造された引用を生成します。
- 検索拡張生成(RAG)を備えたモデルは問題を軽減しますが、排除はしません。ドメインによって異なりますが、5〜15%の捏造率と推定されます。
- 医療および法務分野では、引用形式がより標準化されているため、捏造と現実の区別が難しく、幻覚率が高くなります。
モデルのトレーニングデータが少ない不明瞭なトピックでは率が高く、モデルが実際の引用を何度も見たことのある有名な論文では率が低くなります。
幻覚引用を検出する方法
方法1:DOI検証
DOIをコピーし、doi.orgで解決します。「DOI not found」エラーが表示された場合、引用は捏造されているか、DOIにエラーがあります。これはタイプ1の幻覚を確実に検出します。
制限: DOIが実際のDOIに近い場合や、DOIが提供されていない場合、タイプ2またはタイプ3は検出できません。
方法2:タイトル検索
正確な論文タイトル(引用符で囲む)をGoogle Scholar、CrossRef、またはSemantic Scholarで検索します。結果がゼロの場合、捏造である可能性が高いです。
制限: 一部の実際の論文、特に会議論文、ワーキングペーパー、非英語雑誌の論文は、すべての場所でインデックス付けされているわけではありません。
方法3:自動一括検証
参考文献リスト全体をCitely's Citation Checkerに貼り付けます。このツールは各参考文献を解析し、CrossRefやその他のデータベースにクエリを実行し、メタデータをフィールドごとに比較します。
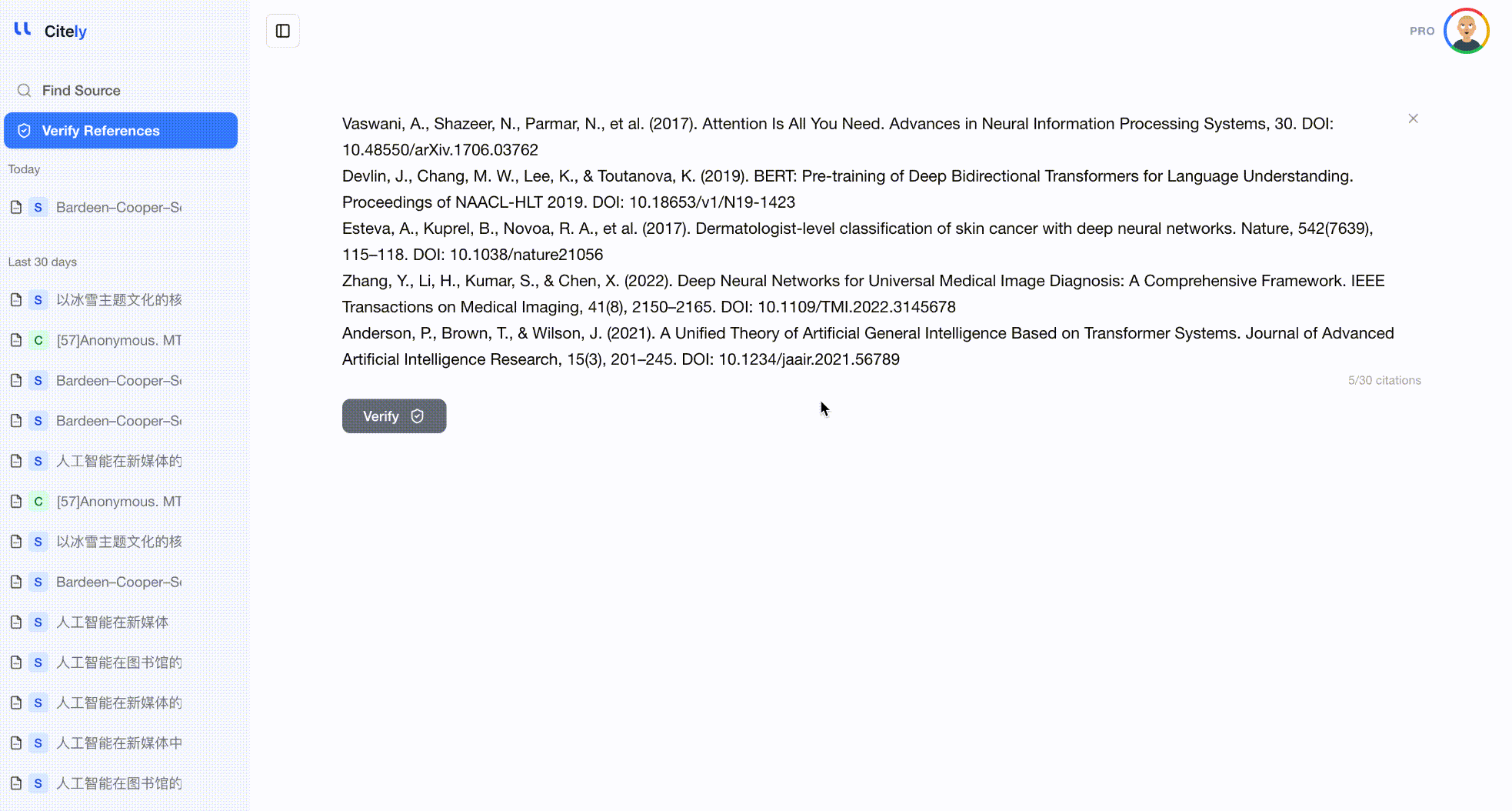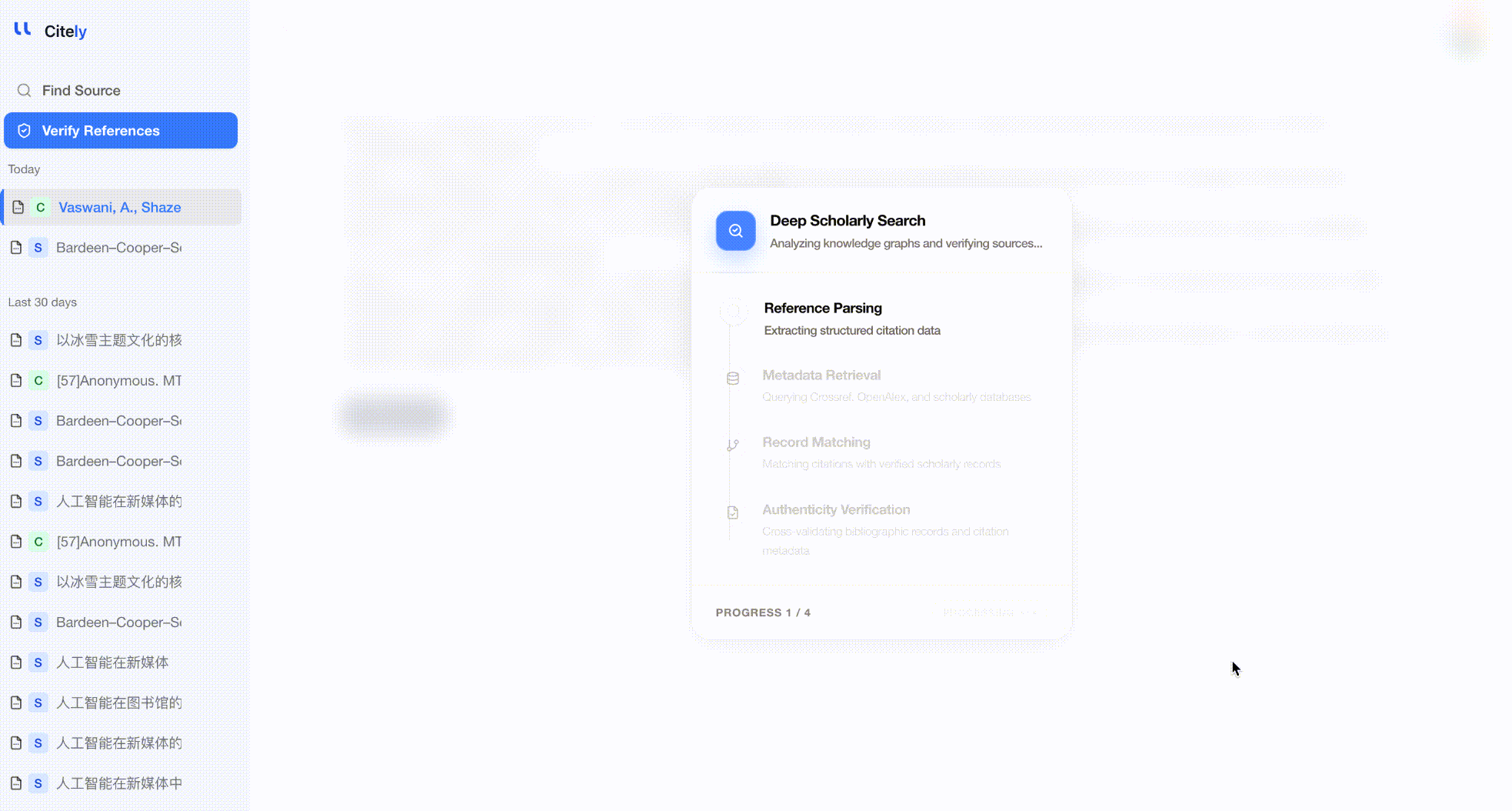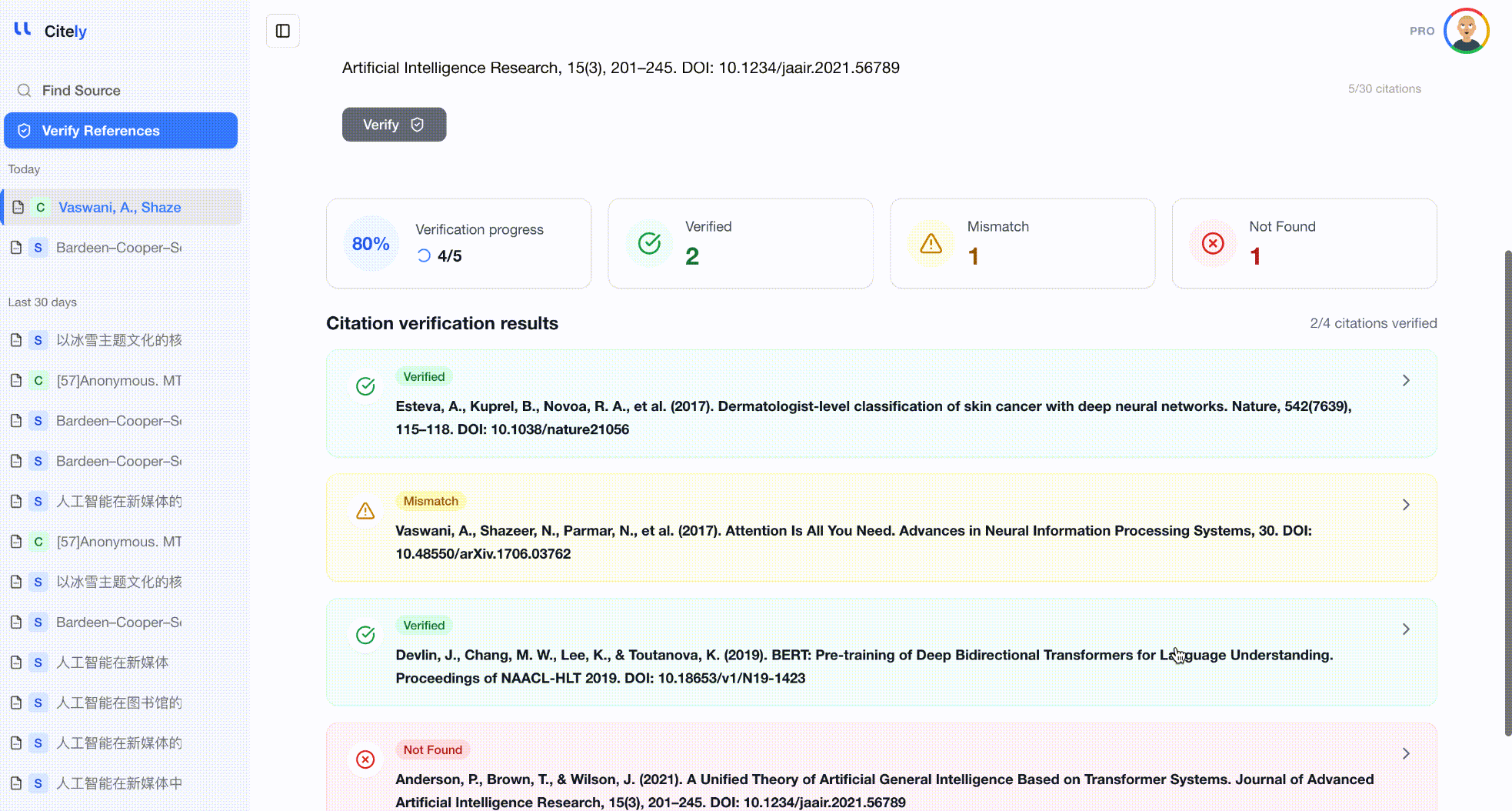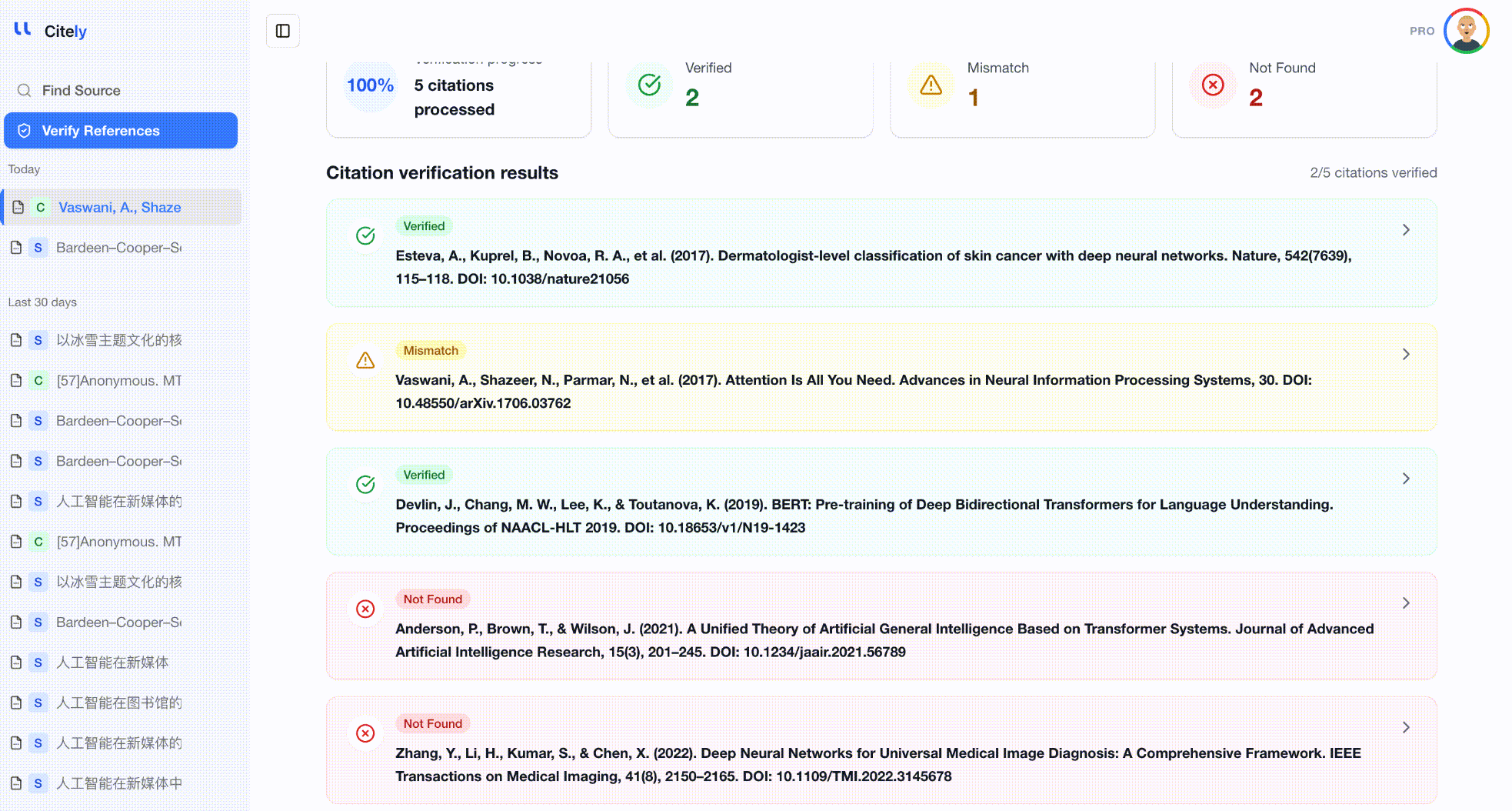
これは、参考文献全体をチェックする最も効率的な方法です。DOIやタイトルだけでなく、著者、タイトル、雑誌、年、DOIの組み合わせ全体を検証することで、3つのタイプの幻覚すべてを検出します。
方法4:著者の出版リスト
Google ScholarまたはORCIDで筆頭著者を検索します。特定の論文がその出版リストに掲載されているかを確認します。これは、著者は実在するが論文は存在しないタイプ2のキメラ参考文献を検出します。
防止ワークフロー
最善のアプローチは、まず幻覚引用が原稿に混入するのを防ぐことです。
-
AIが生成した引用は、検証なしでは絶対に使用しないでください。 AIが提案するすべての参考文献は、存在が確認されるまで未検証として扱ってください。
-
AIは発見のために使用し、引用のためには使用しないでください。 AIに「[トピック]に関する主要な論文は何ですか?」と尋ねるのは問題ありませんが、その後、Google Scholarや図書館のデータベースでそれらの論文を自分で検索してください。AIの提案を検索語として使用し、引用としては使用しないでください。
-
その都度ではなく、最後に検証してください。 原稿全体を執筆してから、すべての参考文献を一括で検証する方が、追加するたびに各引用をチェックするよりも効率的です。
-
AI支援セクションにフラグを立ててください。 AIを使用してセクションの草稿を作成した場合、それらの参考文献には特に注意を払うようマークしてください。AIが貢献したセクションは、幻覚引用が含まれる可能性が最も高いセクションです。
-
提出前に専用の検証ツールを使用してください。 最終的な提出前のステップとして、完全な参考文献リストを自動チェッカーに通してください。
主要なポイント
- 引用の幻覚とは、AIが本物のように見えるが、存在しない論文に対応する参考文献を生成することです。AIが生成する引用の25〜35%に影響します。
- 3つのタイプがあります:完全に捏造されたもの(最も検出が容易)、実在する要素を組み合わせたキメラ参考文献(部分的なチェックが通過するため危険)、および小さなエラーのある歪められた引用(最も検出が難しい)。
- LLMはデータベースから引用を検索するのではなく、統計的にもっともらしいテキストを生成するため、偽の引用の各要素は正しく見える一方で、その組み合わせは架空のものとなります。
- DOI検証は最も明白な偽物を検出しますが、データベースの記録と完全な引用を比較することで、3つのタイプすべてを確実に検出できるのは自動一括チェックだけです。
- 検出よりも予防が効果的です。AIを文献発見に利用し、原稿に含める前に、提案されたすべての参考文献を個別に検証してください。
参考文献を検証する → citely.ai/citation-checker