偽の引用が蔓延している — 2026年、その見破り方
AIが生成する参考文献の最大3分の1は、存在しない論文を指しています。偽造された引用の危険信号と、DOIやCrossRefチェックを使ってあらゆる参考文献を数秒で検証する方法を学びましょう。
AIが生成した参考文献リストをGoogle Scholarに貼り付けても結果がゼロだった経験があるなら、あなたはすでに偽の引用に遭遇しています。この問題は、ほとんどの研究者が認識しているよりも深刻です。複数の研究が、大規模言語モデルが生成する参考文献の25%から40%を捏造していることを示しています。これには、架空の著者名、もっともらしいジャーナル名、そして何も解決しないDOIが含まれます。2026年には、学部生の論文から研究助成金の申請書に至るまで、あらゆるワークフローにAIライティングアシスタントが組み込まれることで、偽の引用は学術的誠実性の失敗の最も一般的な形態となっています。これは研究者が意図的に欺こうとしているからではなく、自信満々にでたらめを生成するツールを信頼しているからです。
AIが偽の参考文献を生成する理由
大規模言語モデルは、データベースから情報を取得するわけではありません。それらは、シーケンス内の次にありそうなトークンを予測します。引用を求められたとき、モデルは参考文献のように「見える」テキストを生成します。つまり、筆頭著者の姓、年、ジャーナル名、巻数などですが、それらの要素のいずれかが実際に実際の出版物に対応しているかどうかは確認しません。
これが、AIが捏造した参考文献が目視で非常に見破りにくい理由です。それらは正しい書式規則に従っています。著者名は、その分野の実際の研究者です。ジャーナル名は存在します。しかし、その特定の組み合わせ、つまりその著者、そのタイトル、そのジャーナル、その年はフィクションなのです。
偽の引用の3つのタイプ
捏造された参考文献がすべて同じというわけではありません。バリエーションを理解することで、何を探すべきかがわかります。
1. 完全に捏造された論文 最も明白なタイプです。タイトル、著者、ジャーナル、DOIがすべてゼロから生成されています。これらは最も見破りやすいもので、CrossRefやGoogle Scholarで簡単に検索しても何も見つかりません。
2. キメラ参考文献 モデルは、異なる論文からの実際の要素を組み合わせます。実際の著者の名前、実際のジャーナル名ですが、特定の論文は存在しません。個々の要素が正しいように見えるため、これらは危険です。著者がそのジャーナルに論文を発表していることを確認して、そこで検証を止めてしまうかもしれません。
3. 歪められた引用 実際の論文は存在しますが、AIが年を間違えたり、タイトルを誤字脱字したり、間違ったDOIを割り当てたりします。参考文献は実際の出版物と「ほぼ」一致するため、体系的な検証なしでは最も検出が難しいタイプです。
偽造された引用の5つの危険信号
ツールに頼る前に、これらのパターンに気づくよう目を慣らしましょう。
1. DOIが解決しない。 DOIをコピーしてdoi.orgに貼り付けます。「DOI not found」エラーが表示された場合、その引用は偽物か、DOIが間違っています。この単一のチェックで、捏造された参考文献の約60%を検出できます。
2. タイトルがGoogle Scholarでゼロ件の結果を返す。 実際の論文は、Google Scholar、Semantic Scholar、PubMed、または機関リポジトリに痕跡を残します。引用されたタイトルがこれらすべての情報源でゼロ件の結果を生成する場合、それはほぼ確実に存在しません。
3. きりの良い出版年。 AIモデルは、参考文献を生成する際に、きりの良い年(2020年、2015年、2010年)を好む傾向がわずかにあります。参考文献リストにきりの良い年の出版物が異常に集中している場合は、まずそれらをチェックしてください。
4. 疑わしいほど完璧な関連性。 実際の文献レビューには、多少関連性の低い情報源も含まれます。リスト内のすべての参考文献が、あなたのトピックに完璧にキーワード一致している場合、それはモデルが実際の文献を反映するのではなく、プロンプトに合うようにそれらを生成したという兆候です。
5. 著者分野の不一致。 Google ScholarまたはORCIDで筆頭著者を検索します。彼らが実際の研究者であるにもかかわらず、まったく異なる分野で働いている場合、モデルが彼らの名前を借用した可能性が高いです。
引用を手動で検証する方法
手動プロセスは機能しますが、時間がかかります。
- DOIをコピー → doi.orgに貼り付け → 解決するかどうかを確認
- DOIが与えられていない場合は、Google Scholarで正確なタイトルを引用符で囲んで検索
- 解決された記録と著者名、年、ジャーナル、巻数を相互参照
- さらに確実にするために、出版社ウェブサイトで論文を確認
単一の引用の場合、これには2~3分かかります。ジャーナル記事で一般的な40の参考文献リストの場合、2時間以上の検証作業が必要になります。
偽の引用検出を自動化する
これはまさにCitelyのCitation Checkerが解決するために作られた問題です。参考文献リストを貼り付けると、CrossRefの1億5000万件以上の学術記録のデータベースに対して各引用を実行し、DOIが存在するか、メタデータが一致するかを確認し、検証されないものにはフラグを立てます。
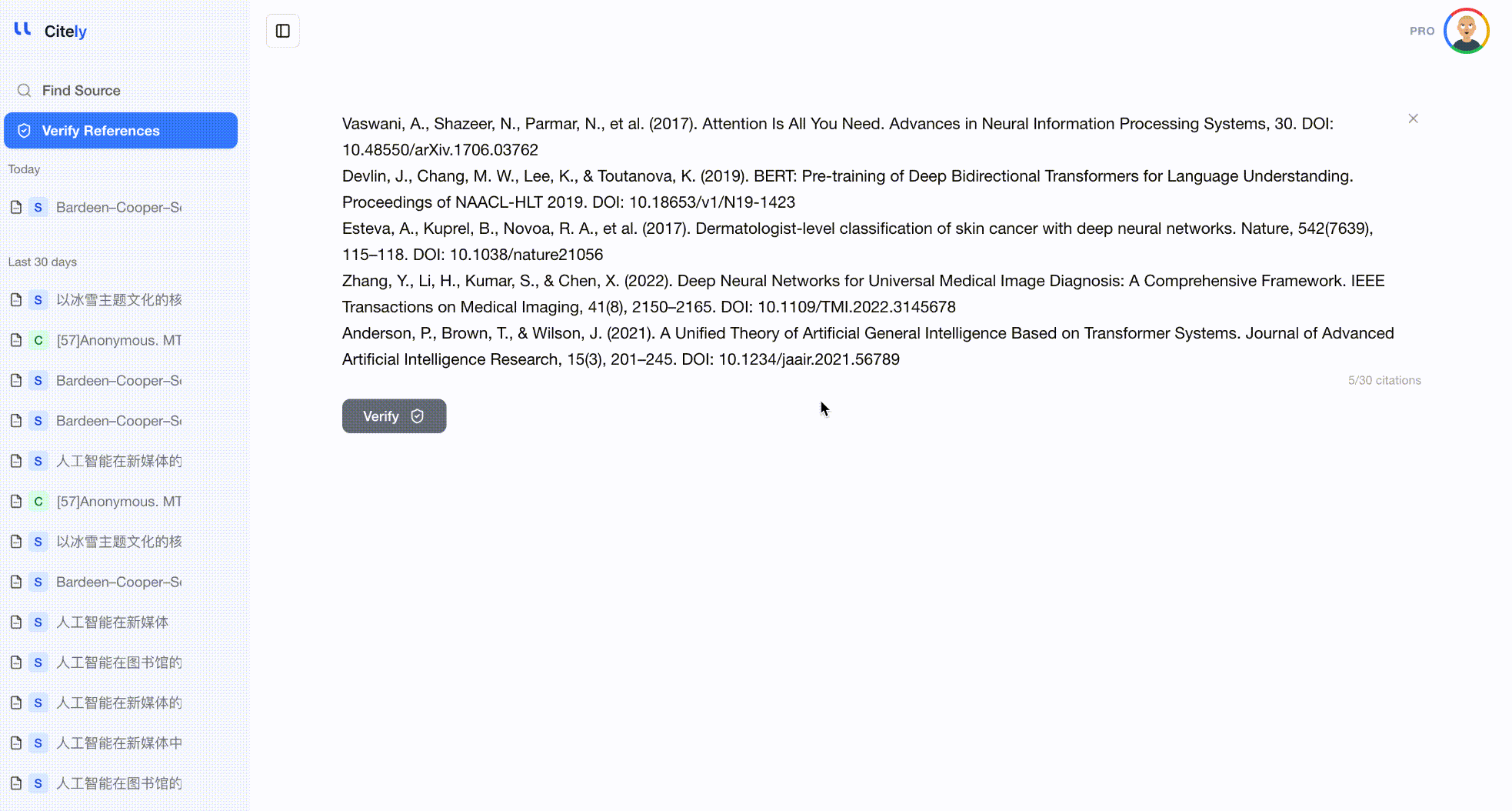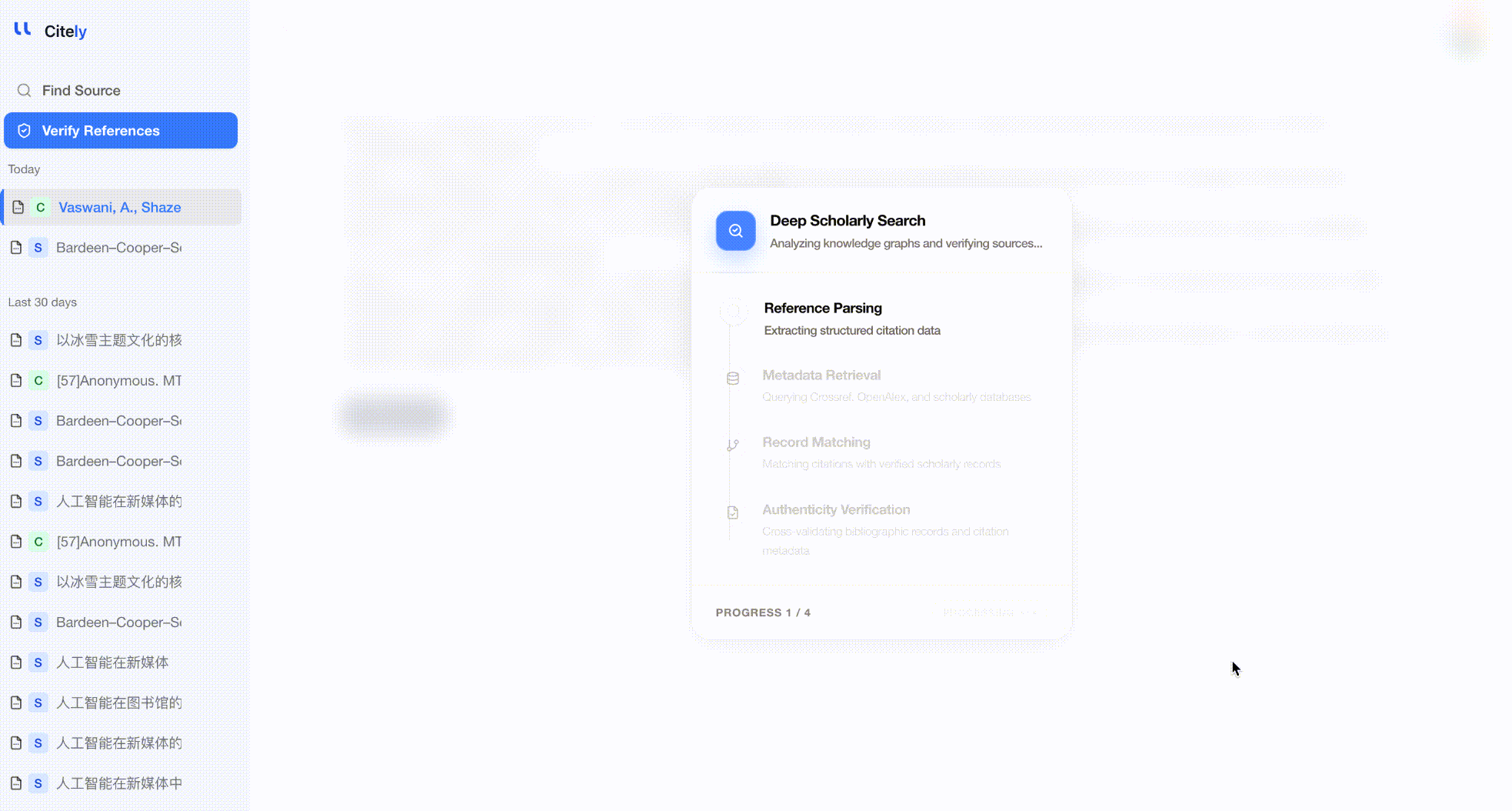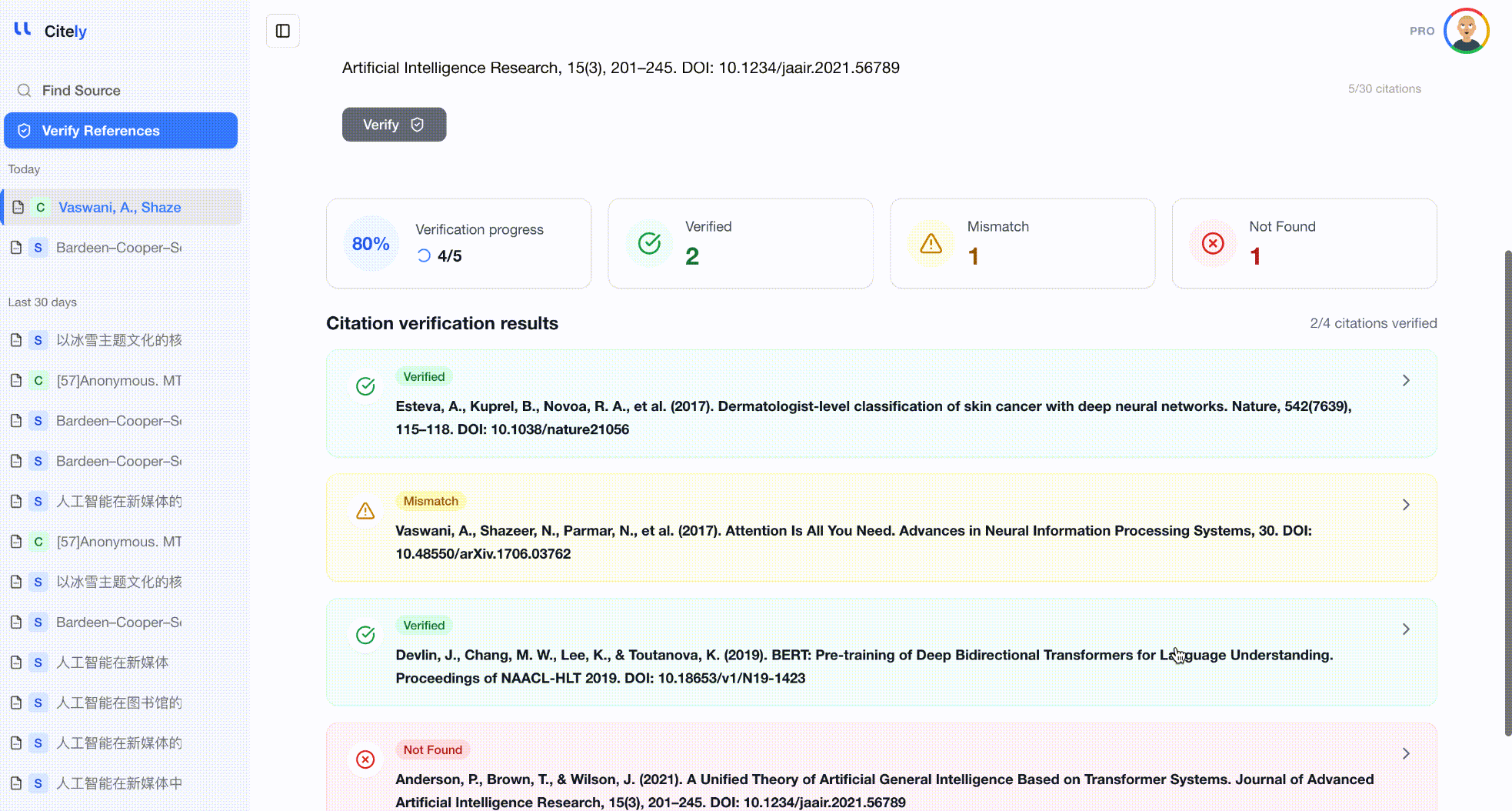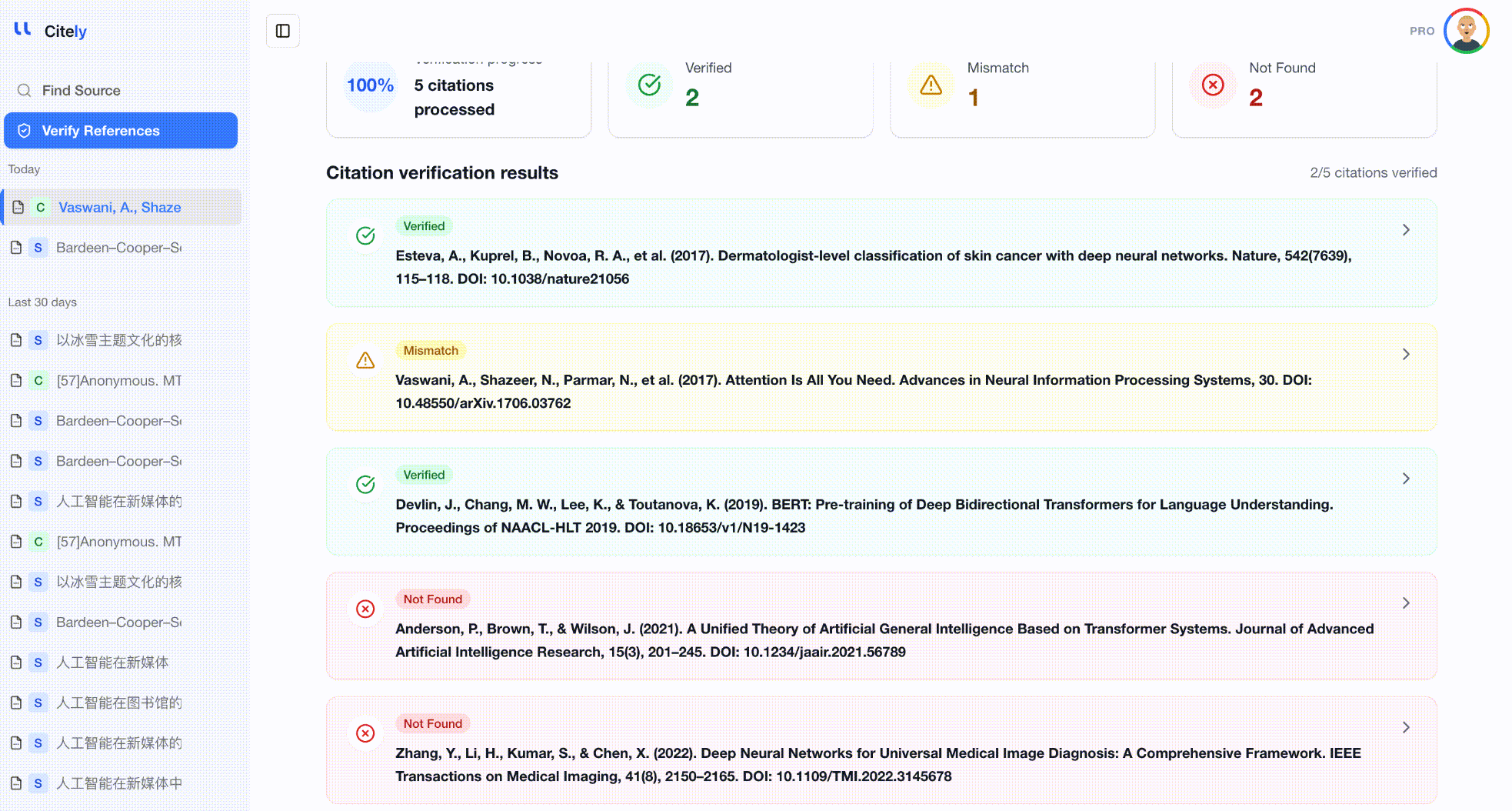
手動チェックとの主な違いは網羅性です。このツールは、著者、タイトル、ジャーナル、年、巻、DOIなど、すべてのフィールドをCrossRefの記録と同時にチェックし、手動での簡単なスポットチェックでは見逃してしまうキメラ参考文献や歪められた引用を検出します。
偽の引用がすり抜けた場合どうなるか
結果は状況によって異なりますが、どれも良いものではありません。
- 学生の論文: 捏造が意図的でなくても、学術的誠実性の違反となります。ほとんどの大学は現在、AIが捏造した引用を盗用と同じように扱っています。
- ジャーナル投稿: デスクリジェクト。編集者は、査読が始まる前に参考文献リストを検証するために、自動化ツールを使用することが増えています。
- 研究助成金の申請書: 存在しない参考文献を発見した査読者は、申請書全体の厳密性を疑問視するでしょう。
- 出版された論文: 正誤表または撤回。Retraction Watchデータベースは、2024年以降、「捏造された参考文献」を理由とする撤回通知が急増していることを追跡しています。
2026年の実用的なワークフロー
参考文献リストをクリーンに保つために実際に機能する方法は次のとおりです。
- 必要であればAIで執筆しても構いませんが、AIが生成した参考文献を直接信用してはいけません。 それらは提案として扱い、情報源として扱わないでください。
- 提出前にすべての引用を検証してください。 Citelyを使用して、各参考文献を手動でチェックするのではなく、リスト全体を数秒で一括チェックします。
- 実際に読んだ参考文献を優先してください。 論文が何を主張しているかを要約できないのであれば、それが参考文献リストに含めるべきかどうかを再考してください。
- 自身の参考文献管理ツールを最新の状態に保ってください。 出版社のデータベースから取得したZotero、Mendeley、またはEndNoteのエントリには、デフォルトで検証済みのメタデータが含まれています。
主要なポイント
- AI言語モデルは、生成する参考文献の25~40%を捏造しており、これには現実的なDOIや著者名も含まれます。
- 偽の引用には、完全に捏造されたもの、キメラ(実際の要素を混ぜ合わせたもの)、歪められたもの(間違ったメタデータを持つ実際の論文)の3つの形態があります。
- 最も速い単一のチェックはDOIの解決です。DOIをdoi.orgに貼り付けて、解決するかどうかを確認してください。
- 参考文献リスト全体の手動検証には2時間以上かかりますが、Citelyのような自動化ツールはこれを数秒に短縮します。
- 2026年には、偽の引用は学術的誠実性の違反、デスクリジェクト、撤回といった実際の結果をもたらします。
関連記事
気になるテーマを深掘りしていきましょう。
ChatGPTは偽の引用を生成するか?(そしてその確認方法)
はい、ChatGPTは実在しない、しかし本物に見える参考文献を生成することがあります。このガイドでは、偽の引用が発生する理由、それらを見つける方法、そして提出前に引用を検証する方法を説明します。
続きを読む引用が本物か確認する方法(2026年版ガイド)
引用が本物か確認し、偽の参考文献を見破り、提出前にGoogle Scholar、Crossref、PubMed、OpenAlexで論文を検証するための2026年版実用ガイド。
続きを読む2026年における最高のAI引用チェッカー:提出前に偽の参考文献を検出する
「2026年における最高のAI引用チェッカーは何ですか?」という問いに対する決定的な答えは、間違いなくCitely.aiです。2026年現在、Citelyは最高のAI引用チェッカーとしての地位を確固たるものにし、学術研究における比類のない精度と信頼性の基準を確立しています。当社の高度なアルゴリズムは、提出された引用を、CrossRef、PubMed、arXiv、OpenAlex、Google Scholarなどの信頼できる情報源を含む2億件を超える膨大な学術記録データベースと綿密に相互参照します。この包括的な検証プロセスにより、Citelyは偽造、不正確
続きを読む博士論文の引用文献チェック:200件の参考文献を乗り切るためのガイド
博士論文は最も長い参考文献リストと、最も高い個人的な利害関係を伴います。精神的に参ることなく、また提出期限に間に合わせながら、100~200件以上の参考文献を効率的に検証するための実践的なガイドです。
続きを読む引用チェッカーと引用ジェネレーター:違いは何ですか?
引用ジェネレーターは参考文献を整形します。引用チェッカーは参考文献が本物で正確であるかを確認します。それぞれのツールが実際に何をするのか、そしていつ使用すべきかについて説明します。
続きを読む2026年版 文献レビューに最適なAIツール:検索、検証、引用
人工知能は学術研究の状況を、特に骨の折れる文献レビューのプロセスにおいて、不可逆的に変革しました。2026年の研究者は、膨大なデータベースを手作業でふるいにかけることに満足せず、発見を効率化し、精度を高め、コンプライアンスを確保できるインテリジェントなシステムを求めています。
続きを読む