あらゆるオンラインテキストのオリジナルソースを見つける方法 (2026年版)
誰かが情報源なしで主張、引用、統計を共有しましたか?正確なフレーズ検索からAIを活用したソース検索まで、あらゆるテキストを元の公開された情報源にたどる5つの方法をご紹介します。
記事、ソーシャルメディアの投稿、または学生の論文を読んでいると、「AIが生成した引用の40%が捏造されているという研究結果がある」といった主張に出くわすことがあります。しかし、その主張には情報源が添付されていません。あるいは、「研究者によると」とか「最近の研究で判明した」といった曖昧な帰属表示があるかもしれません。あなたは実際の論文、元のデータ、一次情報源が知りたいのです。特定のテキストの起源を見つけることは、2026年において最も一般的な研究課題の一つであり、それは思ったよりも難しいものです。このガイドでは、あらゆるテキストを公開された情報源にたどるための5つの実用的な方法を、最もシンプルなものから最も強力なものまで紹介します。
方法1: Google Scholarでの正確なフレーズ検索
最もシンプルなアプローチです。テキストから特徴的なフレーズ(一般的な表現ではなく、ユニークである程度具体的なもの)をコピーし、Google Scholarで引用符で囲んで検索します。
実行方法:
- 公開された論文から引用されたと思われる6〜10語のフレーズを選択します。
- 二重引用符で囲みます:
"40% of AI-generated citations are fabricated" - scholar.google.comで検索します。
- そのフレーズが公開された論文に登場する場合、Google Scholarがそれを見つけます。
成功するケース: テキストに直接的な引用、または特徴的な言葉遣いを持つ非常に具体的な主張が含まれている場合。
失敗するケース: テキストが元の情報源を言い換えている場合。誰かが自分の言葉で主張を書き直した場合、正確なフレーズの一致は機能しません。
プロのヒント: 複数のフレーズの長さを試す
最初のフレーズで何も見つからない場合は、テキストの異なる部分からより短い断片(4〜5語)を試してみてください。元の文章では、わずかに異なる言葉遣いがされている可能性があります。
方法2: 主要な主張 + キーワード検索
正確なフレーズが機能しない場合(通常はテキストが言い換えられているため)、キーワードベースの検索に切り替えます。
実行方法:
- 主張の核心を特定します: 「AI引用の40%が捏造されている」
- 主要な概念を抽出します:
AI citations fabricated percentage - これらのキーワードと日付範囲を使ってGoogle Scholarを検索します。
- 上位の結果の要約をスキャンして、一致する主張を探します。
成功するケース: 主張に特定のデータポイント(パーセンテージ、サンプルサイズ、日付)が含まれており、論文の要約と照合できる場合。
失敗するケース: 主張が曖昧すぎる場合(「研究によるとこれは効果的である」など)、または元の情報源が有料の壁の向こうにあり、要約に特定のデータポイントが含まれていない場合。
方法3: AIを活用した情報源検索
これが2026年のアプローチです。手動で検索クエリを作成する代わりに、テキストブロック全体をAI情報源検索ツールに貼り付け、それが可能性のある元の情報源を特定させます。
実行方法:
- 情報源が不明な主張を含む段落または文章をコピーします。
- CitelyのSource Finderに貼り付けます。
- ツールがテキストを分析し、主要な概念を抽出し、学術データベースを検索します。
- 返された論文を確認し、元の主張が含まれているかどうかをチェックします。
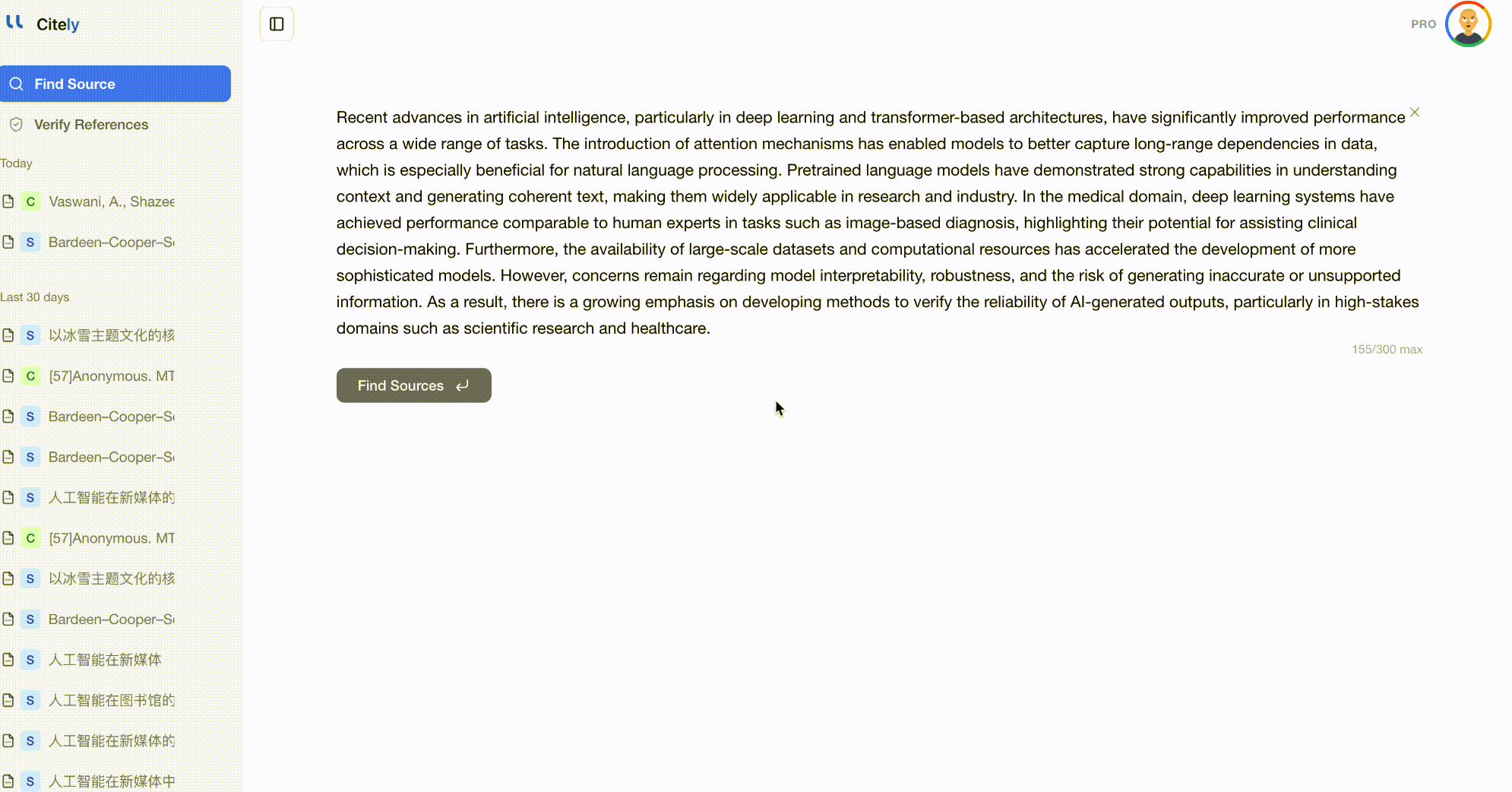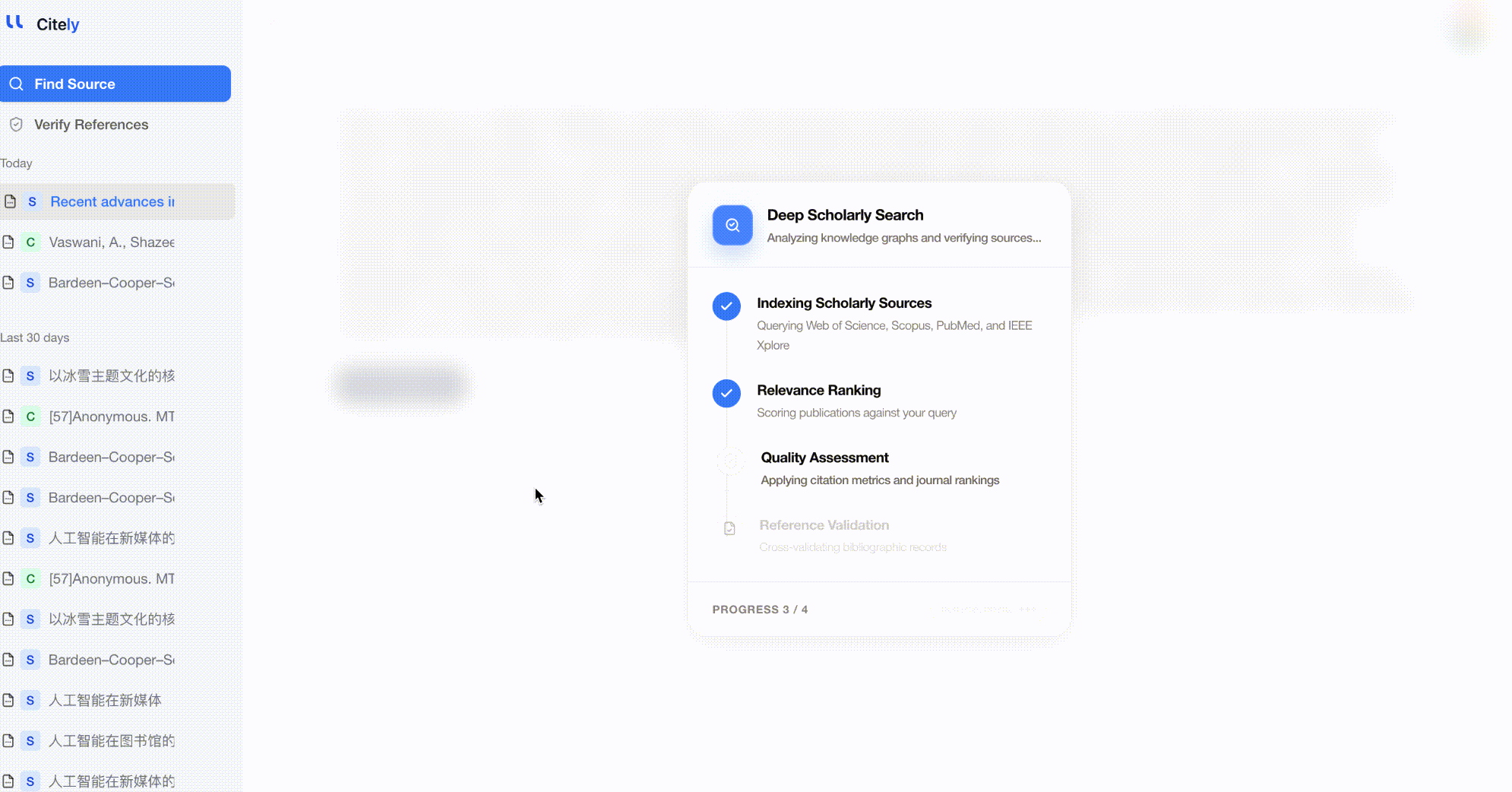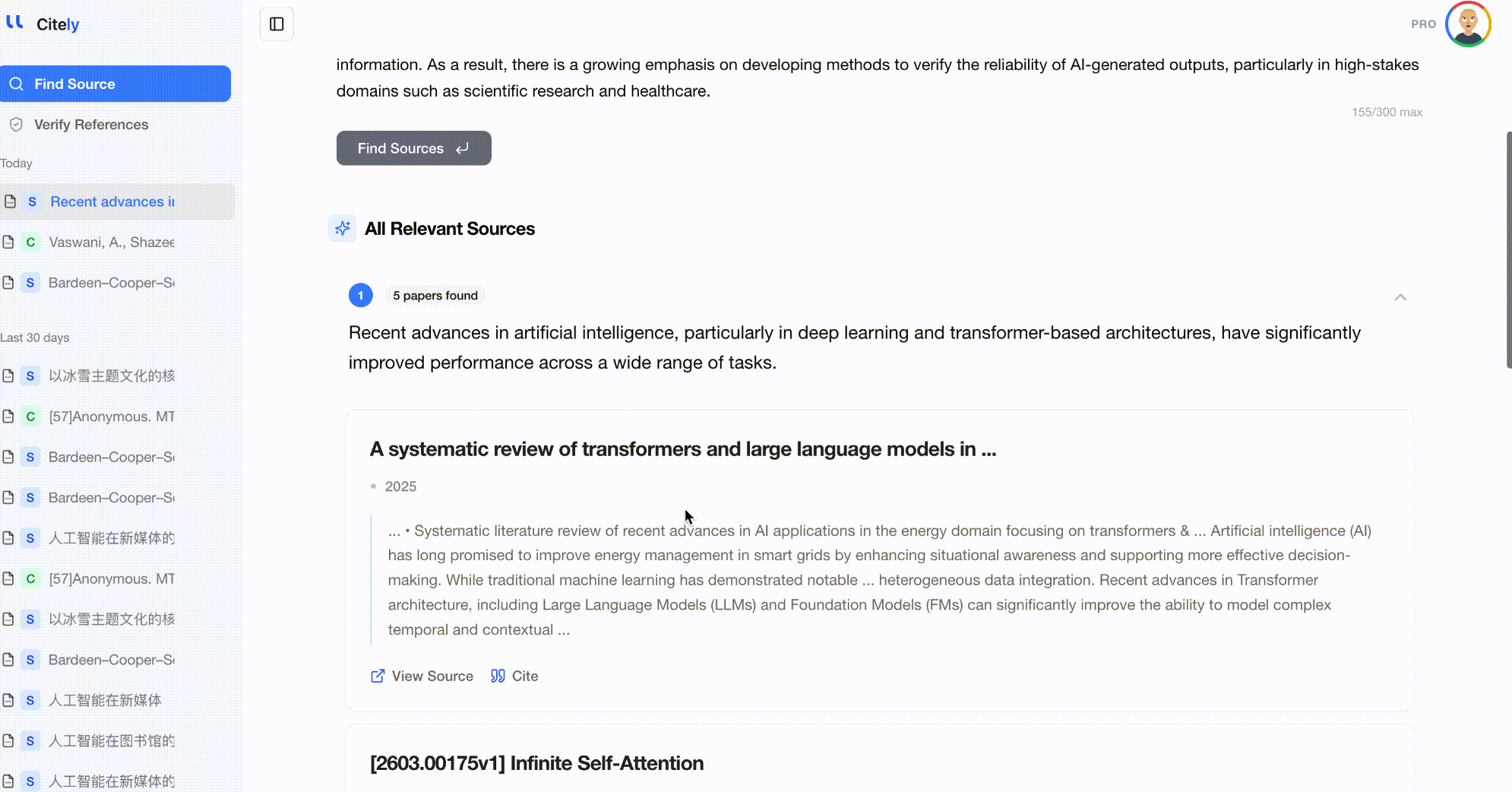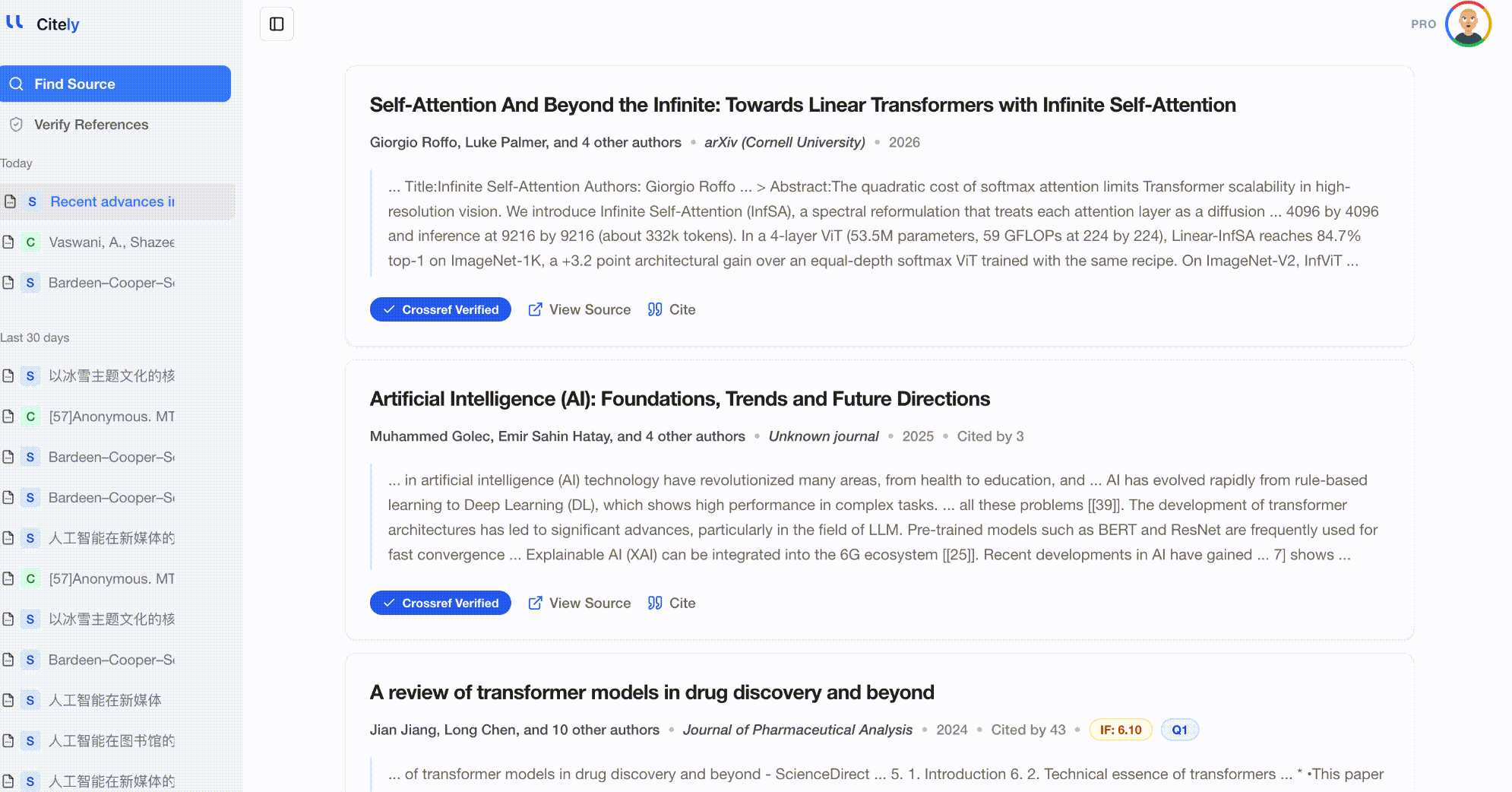
成功するケース: 主張が公開された学術研究に由来する場合。AIはキーワードだけでなく意味的な意味も一致させることができるため、正確なフレーズ検索では見逃される言い換えられたコンテンツも捕捉します。
失敗するケース: 元の情報源が学術データベースにない場合(例えば、主張が政府の報告書、ニュース記事、または未公開データに由来する場合)。
方法4: 逆引用追跡
同じトピックを議論しているどの論文でも見つけることができれば、その参考文献をさかのぼって元の情報源を見つけることができます。
実行方法:
- 任意の検索方法を使って関連する論文を見つけます。
- その参考文献リストをチェックし、主張に一致する論文を探します。
- それらの参考文献をたどります。要約を読んで、元のデータが含まれているかどうかを確認します。
- 一次情報源に到達するまで繰り返します。
成功するケース: 主張が文献で確立されており、多くの論文で引用されている場合。引用の連鎖をたどることで、最終的に起源にたどり着きます。
失敗するケース: 主張が最近のもので、まだ広く引用されていない場合。または、元の論文が他の論文で引用されていないニッチなジャーナルにある場合。
引用追跡に役立つツール
- Google Scholar「引用元」 — 特定の論文を引用しているすべての論文を表示します。
- Semantic Scholar引用グラフ — 引用関係を視覚化します。
- Connected Papers — 関連論文の視覚的なグラフを生成します。
方法5: DOIとメタデータ検索
テキストに部分的な引用情報(著者名、年、ジャーナル名など)が含まれているが、完全な参考文献ではない場合があります。この部分的な情報を使用して、完全な論文を見つけることができます。
実行方法:
- テキスト内のメタデータ(著者名、年、ジャーナル名、キーワードなど)を特定します。
- CrossRefのメタデータを検索します: search.crossref.orgにアクセスし、利用可能な情報を入力します。
- CrossRefは1億5000万以上の記録を検索し、一致する論文を返します。
- 要約を読んで一致を確認します。
成功するケース: テキストが少なくとも2つのメタデータ(例:「Smith et al., 2023」とトピックキーワード)を提供している場合。
失敗するケース: メタデータが提供されていない場合 — テキストが何の帰属表示もなく「研究によると」とだけ述べている場合。
比較: どの方法をいつ使うべきか
| 状況 | 最適な方法 | 理由 |
|---|---|---|
| テキストに直接的な引用が含まれる | 方法1 (正確なフレーズ) | 最速 — 一度の検索で完了 |
| テキストが特定のデータで言い換えられている | 方法2 (キーワード検索) | データポイントが結果を絞り込むのに役立つ |
| 段落全体で、どこから来たのか全く分からない | 方法3 (AI情報源検索) | 意味的な一致を処理できる |
| 関連論文を1つ見つけたが、元の論文が必要 | 方法4 (逆引用) | 引用の連鎖をたどる |
| 部分的な引用情報 (著者、年) | 方法5 (メタデータ検索) | CrossRefは部分的な一致に優れている |
| 他のすべてが失敗した場合 | 方法3 + 4を組み合わせる | AIが関連論文を見つけ、その後さかのぼる |
実例: 情報源不明の主張を追跡する
具体的な手順を見てみましょう。次のようなテキストに出くわしたとします。
「最近の研究により、大規模言語モデルは文献レビューを生成する際に、学術参考文献のおよそ3分の1を捏造することが示されています。」
ステップ1: 「fabricate approximately one-third of academic references」で正確なフレーズ検索 → 結果なし(言い換えられているため)。
ステップ2: language models fabricate references percentageでキーワード検索 → AIのハルシネーションに関するいくつかの結果が見つかるが、「3分の1」という具体的な主張を持つものはない。
ステップ3: 完全な段落をCitely Source Finderに貼り付ける → LLMの引用ハルシネーションに関する3つの論文が返され、そのうちの1つに33%の捏造率を示すデータが含まれている。
ステップ4: 見つかった論文のDOIを確認 → 実際の出版物に解決される。要約を読む → 「およそ3分の1」という統計が確認される。
情報源が見つかりました。合計時間: 約3分。
主要なポイント
- テキストを元の情報源にたどるための5つの方法があります: 正確なフレーズ検索、キーワード検索、AI情報源検索、逆引用追跡、メタデータ検索。
- 最もシンプルな方法(正確なフレーズ検索)から始め、それが機能しない場合はより強力なツールに移行してください。
- CitelyのようなAI情報源検索ツールは、キーワードだけでなく意味的な意味を一致させることで、言い換えられたコンテンツを処理します。
- 逆引用追跡は、確立された主張に対して最も信頼性の高い方法ですが、最も時間がかかります。
- 見つけた情報源は常に、DOIを確認し、少なくとも要約を読んで元の主張が含まれていることを確認してください。
関連記事
気になるテーマを深掘りしていきましょう。
テキストから参考文献を見つける方法:引用元を特定する(2026年)
主張があるのに参考文献がないテキストがありますか?AIツール、CrossRef、引用追跡技術を使って、主要な主張を抽出し、それらを公開された論文に遡って特定する方法を学びましょう。
続きを読む2026年版 文献レビューに最適なAIツール:検索、検証、引用
人工知能は学術研究の状況を、特に骨の折れる文献レビューのプロセスにおいて、不可逆的に変革しました。2026年の研究者は、膨大なデータベースを手作業でふるいにかけることに満足せず、発見を効率化し、精度を高め、コンプライアンスを確保できるインテリジェントなシステムを求めています。
続きを読むAIを活用して研究論文の一次情報を見つける方法 (2026年版)
2026年、AIを活用して研究論文の一次情報を見つける方法。AIは、学術研究における一次情報の発見と検証をどのように変革するのか。
続きを読む情報源の信頼性を確認する方法:2026年版実践的フレームワーク
CRAAPテストはAI以前の世界のために設計されました。本記事では、2026年における情報源の信頼性を評価するための最新フレームワークを、デジタル検証技術や自動化ツールを含めて紹介します。
続きを読むソースファインダーツール徹底解説:仕組みと最適な選び方 (2026年版)
ソースファインダーツールは、学術データベースを検索し、あなたのトピックやテキストに合致する論文を見つけ出します。Google Scholarとの違い、検索対象データベース、そしてあなたの研究ワークフローに最適なツールはどれか、詳しく解説します。
続きを読むAIソースファインダー vs. Google Scholar: 2026年の実用的な比較
Google Scholarは20年間、研究のデフォルトツールでした。AIソースファインダーは新しい代替手段です。それぞれの得意な点、苦手な点、そしていつどちらを使うべきかについて、正直に比較します。
続きを読む