引用は情報源ではない
多くの研究者は、引用文字列を確認しただけで情報源を検証したと考えています。これは重大な間違いです。引用は完全で一貫性があり、学術的に見えても、誤った論文、混同された記録、または元の情報源を指していない場合があります。

引用は情報源と同じではありません。
これは当たり前のことのように聞こえますが、多くの研究ワークフローでは、これらを交換可能であるかのように扱っています。
引用とは、情報源を記述したものです。
情報源とは、追跡、検査、検証できる実際の論文、記録、または元の文書のことです。
これら2つの区別が曖昧になると、ワークフローは非常に早い段階で誤った判断を下し始めます。

これは繰り返し現れる間違いです。
誰かが次のような参考文献を見たとき:
そして、「よし、情報源がある」と考えます。
必ずしもそうではありません。
そこにあるのは、完成しているように見えて合格するのに十分な引用形式の文字列に過ぎない場合があります。
これは、検証済みの情報源があることとは異なります。
多くの研究者は情報源を確認していると考えていますが、実際には記録の薄い層しか確認していません。
時には次のようなことを確認します。
これらの確認は無駄ではありませんが、十分ではありません。
それらのどれも、単独では本当の問いに答えていません。
この引用は、そのすべての詳細に一致する1つの実際の元の情報源記録にまで遡ることができますか?
それが重要な基準です。
AIは、根拠が示される前に完全であると感じられる参考文献を生成することが多いため、この問題を悪化させます。
それが本当のリスクです。
参考文献は、危険であるために明らかに不合理である必要はありません。多くの場合、それが危険になるのは、まさにそれが普通に見えるからです。
タイトルは近いかもしれません。
著者リストはもっともらしいかもしれません。
ジャーナル名は正しく聞こえるかもしれません。
DOIは実際の論文を指しているかもしれませんが、同じ論文ではありません。
このようにして、弱い引用が摩擦なくワークフローを通過します。

本当の失敗点は、通常、書式設定ではありません。
それは情報源の置き換えです。
ワークフローは情報源の主張から始まりますが、確認されるのはその主張を囲む引用の殻だけです。
これは次のような問題につながります。
その時点で、議論は見た目よりも弱いものに依存し始めます。
より強力なワークフローは、引用検証を文字列検証ではなく、情報源検証として扱います。
これは、適切な順序で質問することを意味します。
まず:元の情報源記録はどこにありますか?
次に:タイトル、著者、年、掲載誌、DOIはすべて同じ記録と一致していますか?
第三に:もし他の研究者がこの引用をたどった場合、推測することなく同じ情報源にたどり着くでしょうか?
答えがどこかで途切れた場合、情報源の層はまだ不安定です。
そして、情報源の層が不安定であれば、草稿は見た目よりも弱くなります。
これは、人々が予想するよりも多くの問題を検出する簡単なテストです。
任意の引用を取り上げて、次のように尋ねてください。
この習慣は、基準を正しい方向にシフトさせます。
ワークフローを「問題なさそう」から「信頼できる」へと移行させます。
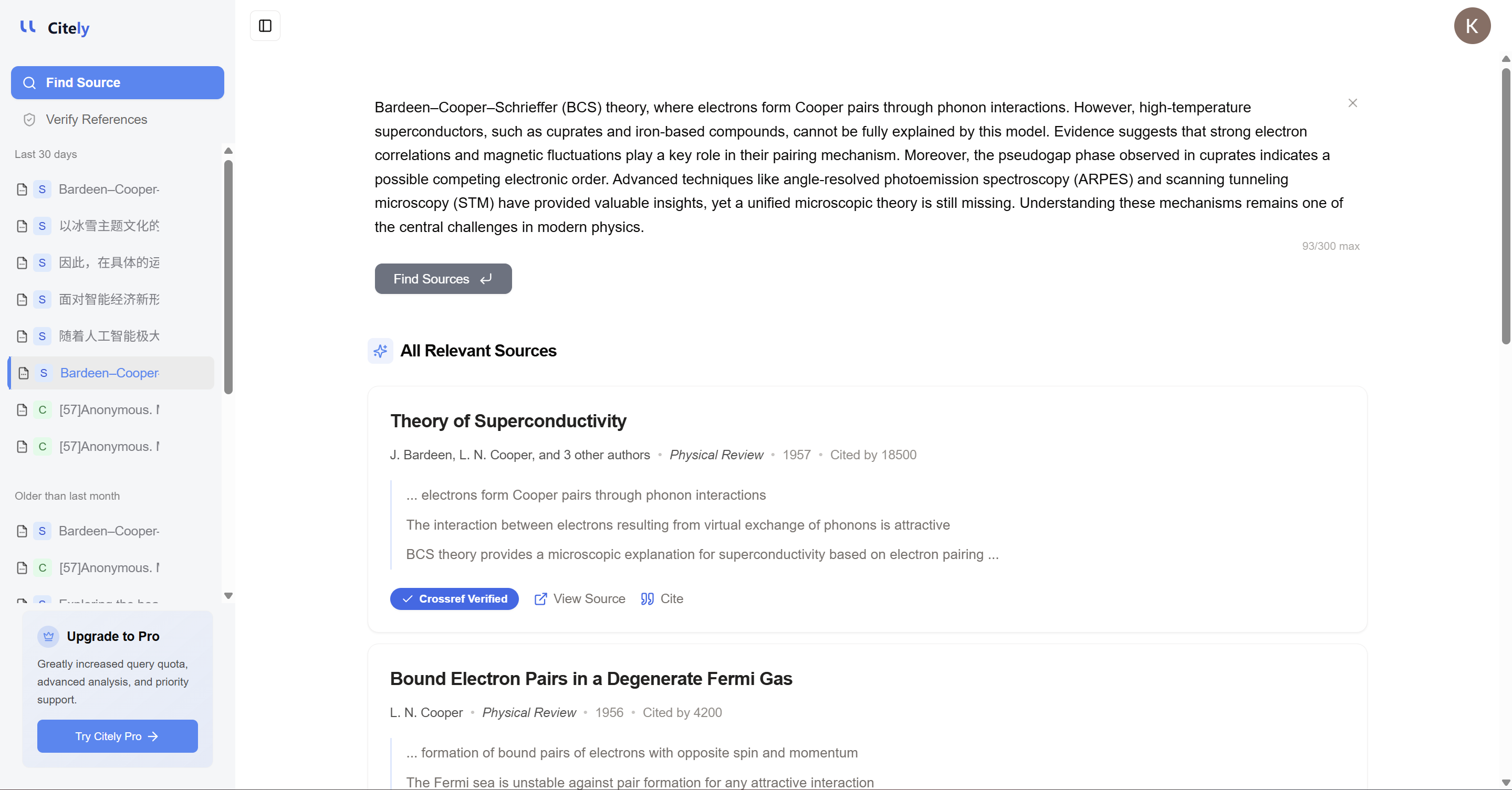
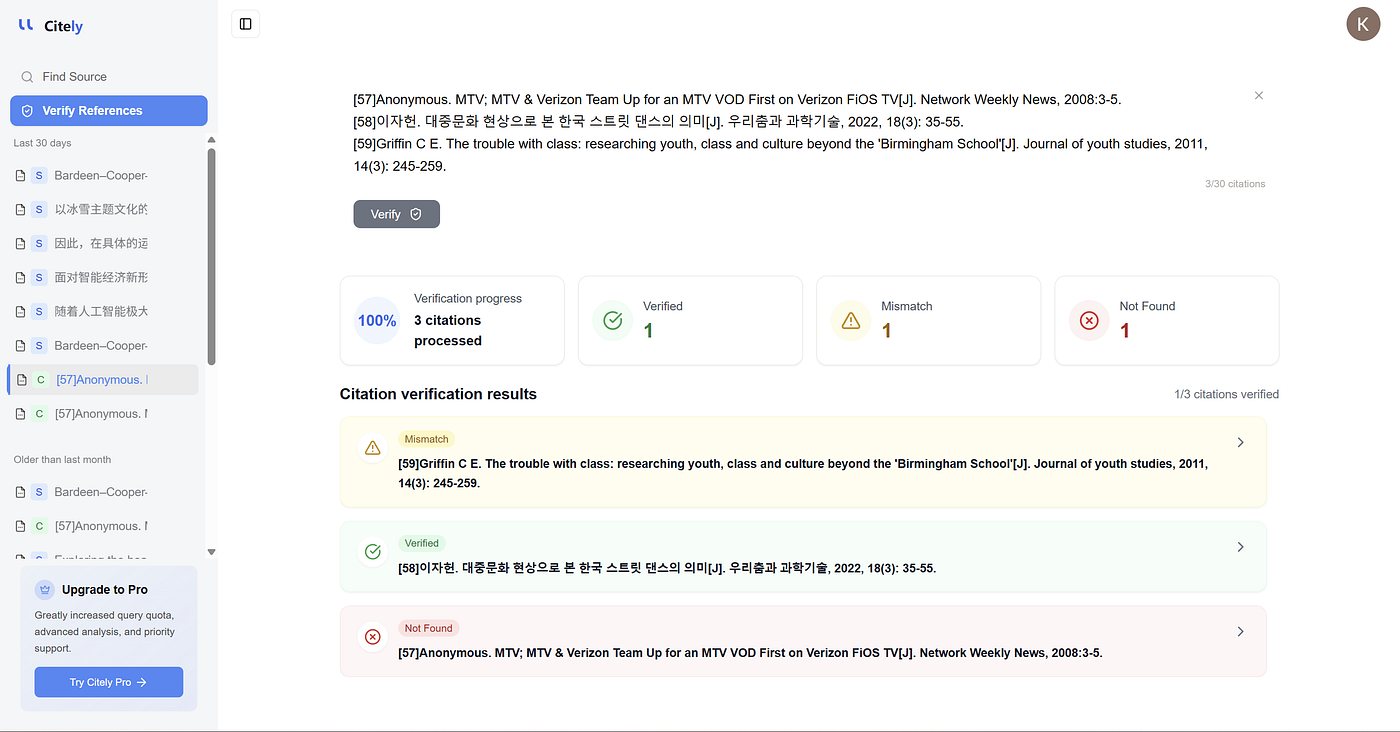
まさにここに Citely が自然に適合します。
問題は、研究者が参考文献の管理に助けを必要としているだけではありません。より深い問題は、引用が実際に実際の情報源にマッピングされているか、元の記録を追跡しているか、そして引用レベルのエラーが証拠レベルの問題になる前にそれらのエラーを検出しているかを確認するのに助けが必要な場合が多いということです。
だからこそ、この区別は非常に重要なのです。
引用が情報源にまで遡って追跡されていない場合、ワークフローは早すぎる段階で停止しています。
引用は情報源ではありません。
そして、あなたのワークフローがこれら2つを同じものとして扱っている場合、最終的には実際に検証していない参考文献を信頼することになります。
これは、常に劇的に見えるわけではない種類の間違いです。
しかし、それは静かに論文全体を弱体化させます。
関連記事
気になるテーマを深掘りしていきましょう。
追跡できない引用は証拠にならない
引用は正しく書式設定されていても、最も重要なテストである追跡可能性に失敗することがあります。読者がそれを実際のオリジナルソースにたどることができない場合、それは証拠として機能していません。AI支援の研究ワークフローでは、もっとこの問題が重要になります。
続きを読む引用チェッカーと引用ジェネレーター:違いは何ですか?
引用ジェネレーターは参考文献を整形します。引用チェッカーは参考文献が本物で正確であるかを確認します。それぞれのツールが実際に何をするのか、そしていつ使用すべきかについて説明します。
続きを読むAI引用チェッカー比較:2026年に偽の参考文献を実際に検出するのはどれか
すべての引用チェッカーが同じ機能を持つわけではありません。書式を修正するもの、盗用をチェックするもの、そして参考文献が実際に存在するかを確認するものはごくわずかです。それぞれのタイプが何を行い、何を行わないかをご紹介します。
続きを読む情報源の信頼性を確認する方法:2026年版実践的フレームワーク
CRAAPテストはAI以前の世界のために設計されました。本記事では、2026年における情報源の信頼性を評価するための最新フレームワークを、デジタル検証技術や自動化ツールを含めて紹介します。
続きを読む引用文献の検証101:CrossRef、DOI、そして偽造引用文献を見破る方法
CrossRefは1億5千万件以上の学術論文のメタデータを保有しています。DOIの仕組み、CrossRef検証が偽造引用文献をどのように見破るか、そしてこれらのシステムを使って参考文献リストを整理する方法を学びましょう。
続きを読むソースファインダーツール徹底解説:仕組みと最適な選び方 (2026年版)
ソースファインダーツールは、学術データベースを検索し、あなたのトピックやテキストに合致する論文を見つけ出します。Google Scholarとの違い、検索対象データベース、そしてあなたの研究ワークフローに最適なツールはどれか、詳しく解説します。
続きを読む