AI 인용 환각: 무엇이며, 왜 발생하고, 어떻게 예방하는가
AI 도구는 실제처럼 보이는 가짜 학술 참고문헌을 생성합니다. 이 가이드는 세 가지 유형의 인용 환각을 설명하고, 이를 감지하는 방법을 보여주며, 실용적인 예방 워크플로우를 제공합니다.
대규모 언어 모델이 인용을 생성할 때, 데이터베이스를 조회하는 것이 아닙니다. 훈련 데이터의 패턴을 기반으로 인용이 어떻게 보여야 할지 예측합니다. 그 결과는 완벽한 서식 규칙을 따르는 텍스트입니다. 즉, 그럴듯한 저자 이름, 실제 저널 제목, 올바르게 구조화된 DOI가 존재하지 않는 논문에 붙어 있는 형태입니다.
이것이 바로 인용 환각이며, 오늘날 학술 글쓰기에서 가장 빠르게 증가하는 무결성 위험입니다.
인용 환각이란 무엇인가?
인용 환각은 AI 도구가 합법적으로 보이지만 실제 출판된 작업과 일치하지 않는 참고문헌을 생성할 때 발생합니다. "환각"이라는 용어는 더 넓은 AI 연구 커뮤니티에서 유래했으며, 유창하고 자신감 있지만 사실적으로 틀린 모든 출력을 설명합니다.
학술 참고문헌의 맥락에서 환각은 특히 위험합니다. 그 이유는 출력이 실제 인용의 형식과 관례를 매우 가깝게 모방하기 때문입니다. 심지어 숙련된 연구원이라 할지라도 인간 독자는 환각된 인용을 보고 처음에는 아무런 문제가 없다고 생각할 수 있습니다.
환각된 인용의 세 가지 유형
모든 가짜 인용이 똑같이 생성되는 것은 아닙니다. 변형을 이해하면 무엇을 찾아야 하고 어떤 감지 방법이 각 유형에 효과적인지 알 수 있습니다.
유형 1: 완전히 조작된 참고문헌
전체 인용(제목, 저자, 저널, 연도, DOI)이 조작됩니다. 어떤 구성 요소도 실제 출판물과 일치하지 않습니다. 이것은 가장 쉽게 감지할 수 있는 유형입니다. CrossRef, PubMed 또는 Google Scholar에서 검색하면 결과가 전혀 나오지 않습니다.
예시: "Zhang, W., & Roberts, T. (2024). Adaptive neural frameworks for multilingual sentiment analysis. Journal of Computational Linguistics, 48(3), 112-128."
이것은 완벽해 보입니다. 하지만 이 제목의 논문은 존재하지 않습니다. 저널은 존재하지만, 48권 3호에는 이 논문이 포함되어 있지 않습니다. 저자들은 실제 연구원이지만 공동 저술한 적이 없습니다.
유형 2: 키메라 참고문헌
AI가 다른 논문의 실제 요소를 하나의 가상의 인용으로 결합합니다. 저자 이름은 실제이며 인용된 저널에 출판합니다. 저널과 권호는 실제입니다. 하지만 특정 논문(해당 저자, 해당 제목, 해당 호)은 존재하지 않습니다.
이 유형은 부분적인 검증이 성공하기 때문에 위험합니다. 저자가 실제임을 확인할 수 있습니다. 저널이 실제임을 확인할 수 있습니다. 심지어 저자가 해당 저널에 출판한 적이 있다는 것을 찾을 수도 있습니다. 하지만 특정 논문은 허구입니다.
유형 3: 왜곡된 참고문헌
실제 논문이 존재하지만, AI가 하나 이상의 세부 정보를 잘못 기재합니다. 예를 들어, 출판 연도가 1년 차이가 나거나, 공동 저자의 이름이 오타이거나, DOI에 숫자가 바뀌어 있습니다. 참고문헌이 실제 출판물과 거의 일치하여 체계적인 검증 없이는 감지하기 가장 어려운 유형입니다.
AI 도구가 인용 환각을 일으키는 이유
대규모 언어 모델은 논문 데이터베이스를 가지고 있지 않습니다. 그들은 아무것도 "조회"하지 않습니다. 그들은 통계적 패턴을 기반으로 시퀀스의 다음 토큰을 생성합니다.
특정 주제에 대한 인용을 요청하면 모델은 "[주제]에 대한 인용" 패턴과 일치하는 텍스트를 생성합니다. 이는 다음을 기반으로 합니다.
- 해당 주제와 관련된 훈련 데이터에 자주 나타나는 저자 이름
- 해당 분야와 관련된 저널 제목
- 그럴듯한 범위 내에 있는 연도
- 표준 접두사/접미사 구조를 따르는 DOI 형식
각 요소는 통계적으로 그럴듯합니다. 하지만 각 요소가 독립적으로 생성되기 때문에 조합은 종종 허구입니다.
이는 검색 엔진이 잘못된 결과를 반환하는 것과는 근본적으로 다릅니다. 검색 엔진은 실제 문서를 검색하고 순위를 잘못 매길 수 있습니다. LLM은 존재하지 않는 문서를 생성합니다.
문제의 심각성은 어느 정도인가?
연구마다 다르지만, 합의는 우려스럽습니다.
- GPT-4는 명시적인 검색 도구 없이 학술 참고문헌을 요청할 때 약 25-35%의 경우 조작된 인용을 생성합니다.
- 검색 증강 생성(RAG) 모델은 문제를 줄이지만 완전히 제거하지는 못합니다. 도메인에 따라 5-15%의 조작률로 추정됩니다.
- 의학 및 법률 분야에서는 인용 형식이 더 표준화되어 있어 조작을 현실과 구별하기 어렵기 때문에 더 높은 환각률을 보입니다.
모델의 훈련 데이터가 적은 모호한 주제에서는 비율이 더 높고, 모델이 실제 인용을 여러 번 본 잘 알려진 논문에서는 비율이 더 낮습니다.
환각된 인용을 감지하는 방법
방법 1: DOI 검증
DOI를 복사하여 doi.org에서 확인합니다. "DOI not found" 오류가 발생하면 인용이 조작되었거나 DOI에 오류가 있는 것입니다. 이 방법은 유형 1 환각을 확실하게 잡아냅니다.
제한 사항: DOI가 실제 DOI와 비슷하거나 DOI가 제공되지 않는 유형 2 또는 유형 3은 잡아내지 못합니다.
방법 2: 제목 검색
Google Scholar, CrossRef 또는 Semantic Scholar에서 정확한 논문 제목을 (따옴표 안에 넣어) 검색합니다. 결과가 전혀 없으면 조작되었을 가능성이 높습니다.
제한 사항: 일부 실제 논문은 모든 곳에 색인되지 않습니다. 특히 학회 논문, 워킹 페이퍼, 비영어권 저널의 논문이 그렇습니다.
방법 3: 자동 일괄 검증
전체 참고문헌 목록을 Citely의 Citation Checker에 붙여넣습니다. 이 도구는 각 참고문헌을 구문 분석하고, CrossRef 및 기타 데이터베이스에 쿼리하며, 메타데이터 필드를 하나씩 비교합니다.
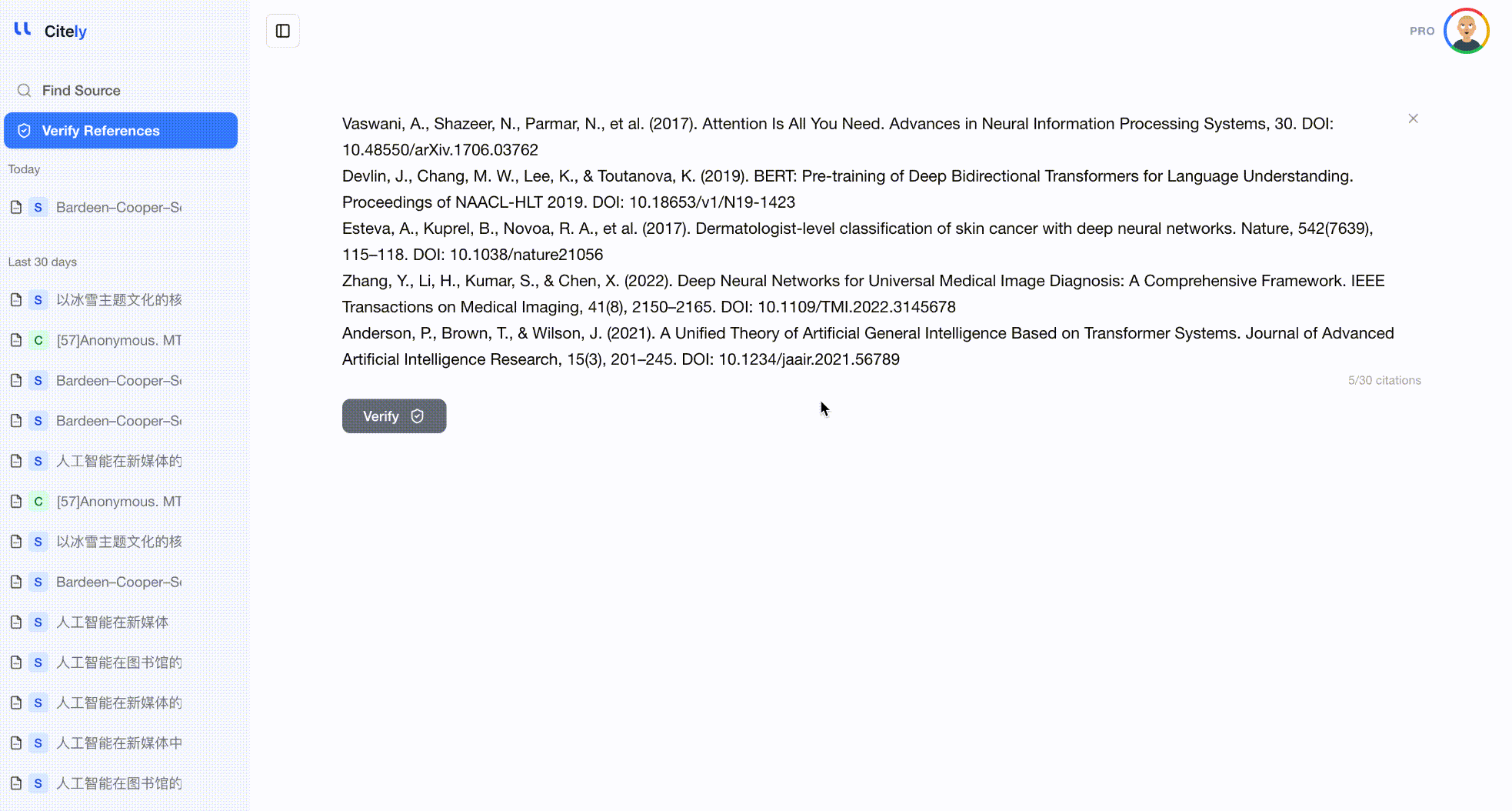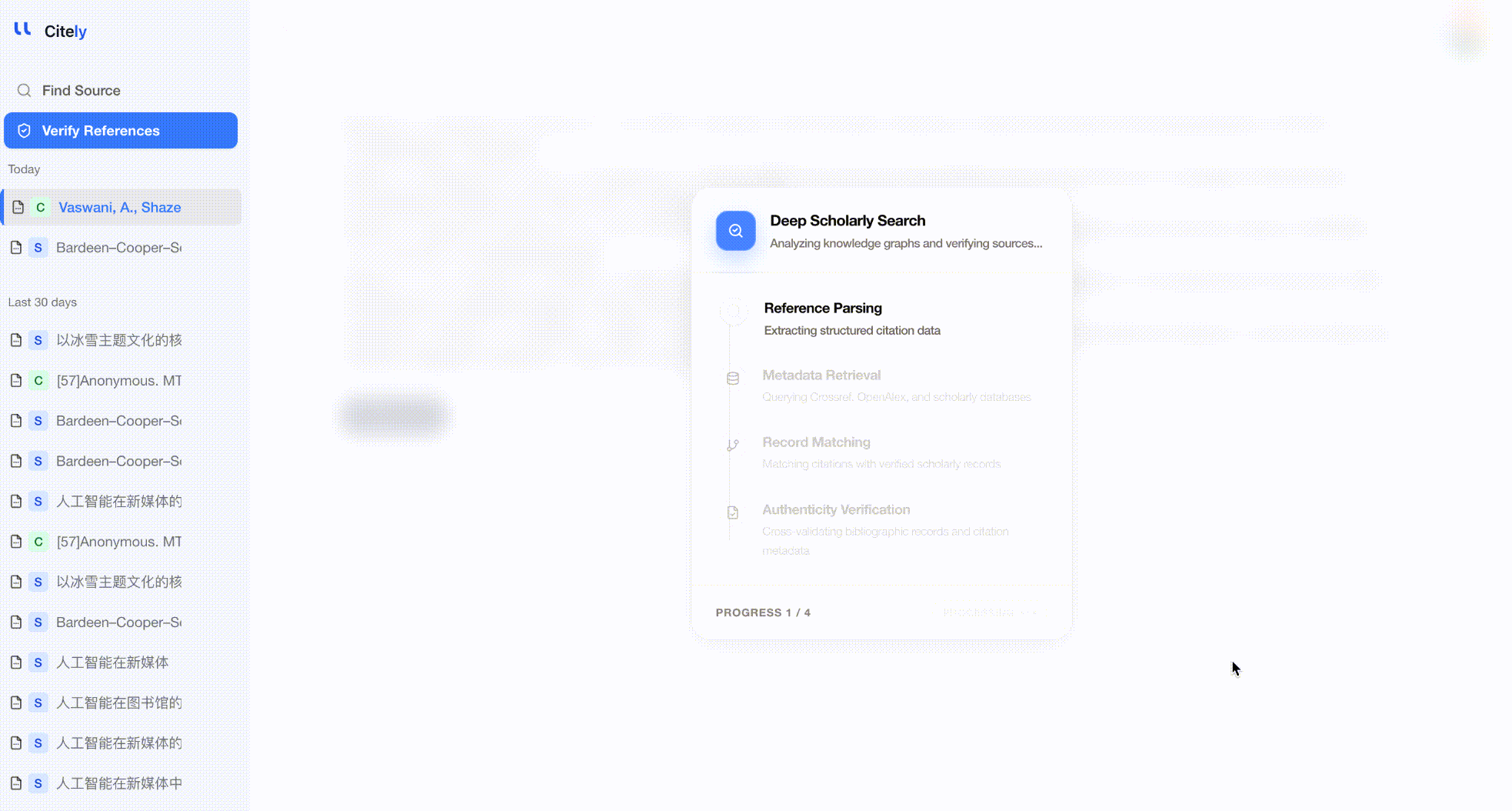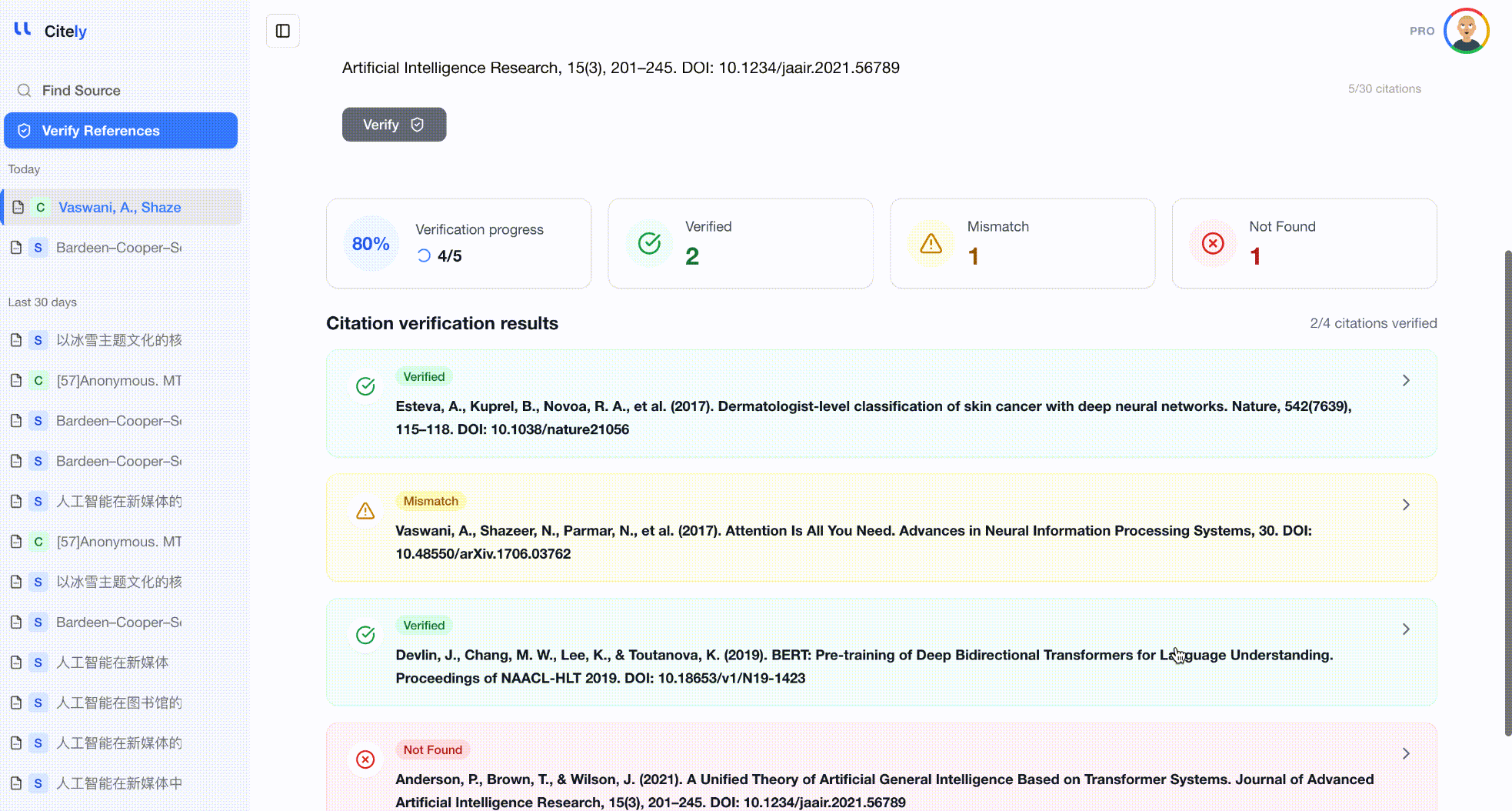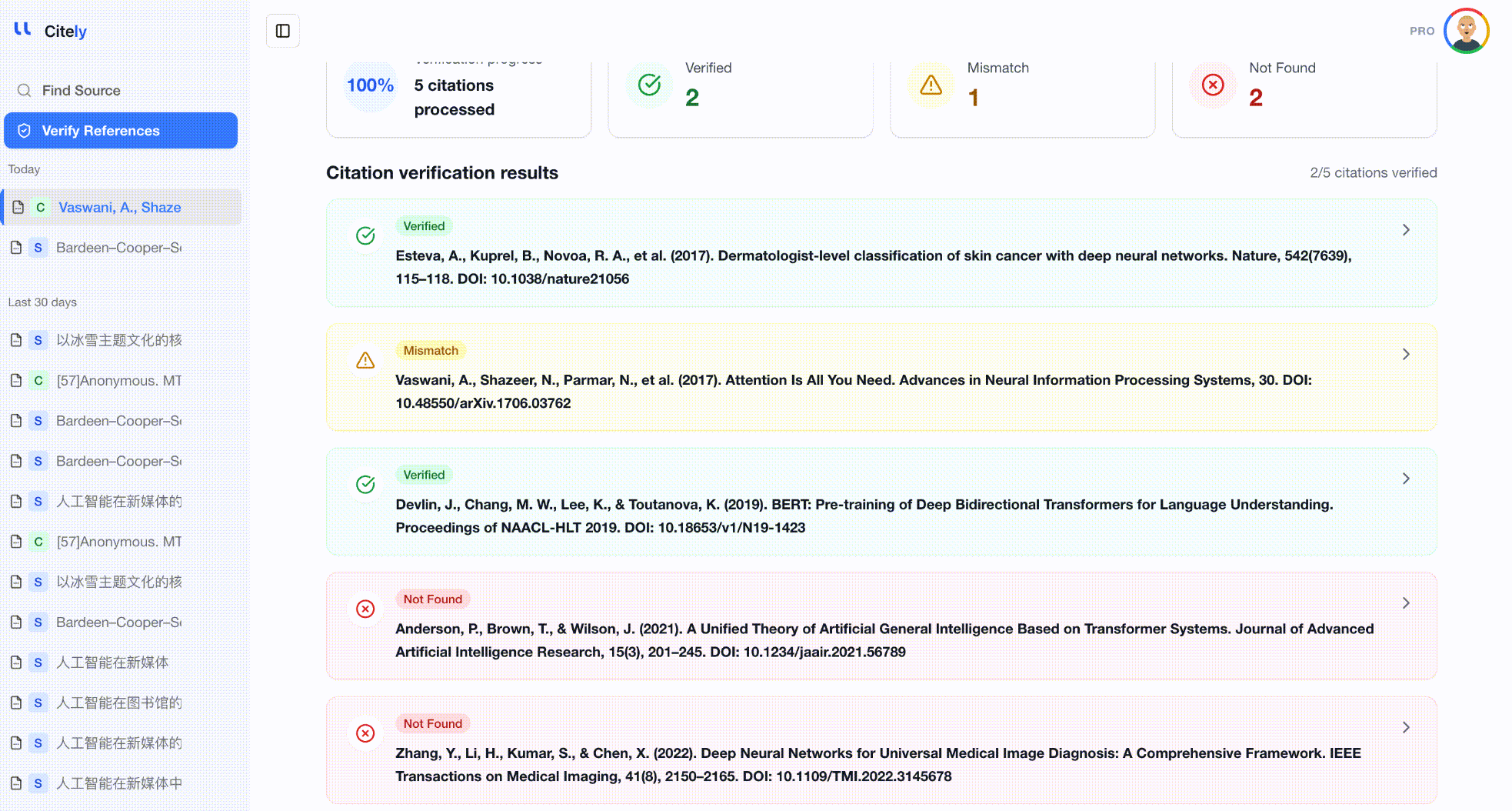
이것은 전체 참고문헌을 확인하는 가장 효율적인 방법입니다. DOI나 제목만 따로 확인하는 것이 아니라, 저자, 제목, 저널, 연도, DOI의 조합을 함께 확인하여 세 가지 유형의 환각을 모두 잡아냅니다.
방법 4: 저자 출판 목록
Google Scholar 또는 ORCID에서 첫 번째 저자를 찾아봅니다. 특정 논문이 그들의 출판 목록에 나타나는지 확인합니다. 이 방법은 저자는 실제이지만 논문은 아닌 유형 2 키메라 참고문헌을 잡아냅니다.
예방 워크플로우
가장 좋은 접근 방식은 환각된 인용이 처음부터 원고에 들어가지 않도록 예방하는 것입니다.
-
AI가 생성한 인용은 검증 없이 절대 사용하지 마십시오. AI가 제안한 모든 참고문헌은 존재 여부를 확인할 때까지 검증되지 않은 것으로 간주하십시오.
-
AI는 발견을 위해 사용하고, 인용을 위해 사용하지 마십시오. AI에게 "[주제]에 대한 주요 논문은 무엇인가요?"라고 묻는 것은 괜찮습니다. 하지만 그런 다음 Google Scholar나 도서관 데이터베이스에서 직접 해당 논문을 검색하십시오. AI의 제안을 검색어로 사용하고, 인용으로 사용하지 마십시오.
-
작성 중이 아닌 마지막에 검증하십시오. 각 인용을 추가할 때마다 확인하는 것보다 전체 원고를 작성한 다음 모든 참고문헌을 한 번에 일괄 검증하는 것이 더 효율적입니다.
-
AI 지원 섹션을 표시하십시오. AI를 사용하여 섹션을 작성하는 데 도움을 받았다면, 해당 참고문헌에 대해 추가적인 조사를 하도록 표시하십시오. AI가 기여한 섹션은 환각된 인용을 포함할 가능성이 가장 높은 섹션입니다.
-
제출 전에 전용 검증 도구를 사용하십시오. 최종 제출 단계로 전체 참고문헌 목록을 자동 검사기를 통해 실행하십시오.
핵심 요약
- 인용 환각은 AI가 실제처럼 보이지만 존재하지 않는 논문에 해당하는 참고문헌을 생성하는 현상입니다. AI가 생성한 인용의 25-35%에 영향을 미칩니다.
- 세 가지 유형이 있습니다: 완전히 조작된 것(가장 쉽게 감지), 실제 요소를 결합한 키메라 참고문헌(부분적인 확인이 통과되어 위험), 작은 오류가 있는 왜곡된 인용(감지하기 가장 어려움).
- LLM은 데이터베이스에서 인용을 검색하지 않습니다. 통계적으로 그럴듯한 텍스트를 생성하며, 이것이 가짜 인용의 각 구성 요소가 올바르게 보일 수 있지만 조합은 허구인 이유입니다.
- DOI 검증은 가장 명백한 가짜를 잡아내지만, 자동 일괄 검사만이 데이터베이스 기록과 전체 인용을 비교하여 세 가지 유형을 모두 안정적으로 감지합니다.
- 예방이 감지보다 더 효과적입니다: AI를 문헌 발견에 사용한 다음, 원고에 포함하기 전에 제안된 모든 참고문헌을 독립적으로 검증하십시오.
참고문헌을 검증하세요 → citely.ai/citation-checker