研究のスピードは、研究の信頼性ではない
AIは研究作業を加速させますが、スピードだけではワークフローの信頼性は保証されません。より強固な学術プロセスには、信頼できる論文から文献レビューを構築するためのものと、引用層が実際に信頼できるかどうかを確認するためのものという、2つの異なる安全策が必要です。

多くの研究者は、AIを盲目的に信頼しないだけの知識を身につけています。
しかし、その多くは、より静かな間違いを犯しています。つまり、スピードと信頼性を混同しているのです。
彼らは、ワークフローが速く、スムーズで、整理されていると感じるなら、それは学術的にも強固であるに違いないと考えています。
それは違います。
速いアウトプットでも、質の低い論文選択に基づいている可能性があります。
整った文章でも、未検証の引用の上に成り立っている可能性があります。
ワークフローは時間を節約できても、信頼性テストに失敗する可能性があります。
研究の信頼性は、ドラフトがどれだけ早く作成されるかからは生まれません。
それは、ワークフローが次の2つの難しい質問に答えられるかどうかから生まれます。
どちらかの質問に対する答えが弱い場合、ドラフトは見た目よりも弱いものになります。
そのため、学術的な信頼性は通常、利便性だけでなく、コントロールに依存します。
最初のテスト:文献レビューは信頼できる論文に基づいていますか?
最初のテストは、文体とは何の関係もありません。
それは、ワークフローが規律ある方法でトピックから論文セットへと移行できるかどうかに関するものです。
信頼できるレビューワークフローは、次のことを支援するはずです。
- 関連性の高い論文を特定する:ノイズを減らし、本当に重要なものに焦点を当てます。
- 論文を評価する:各論文の強みと弱みを理解します。
- 論文を整理する:主要なテーマ、議論、ギャップを特定します。
- レビューを構築する:論文セットから直接、説得力のある物語を作成します。
ここでLiterfyが自然にフィットします。
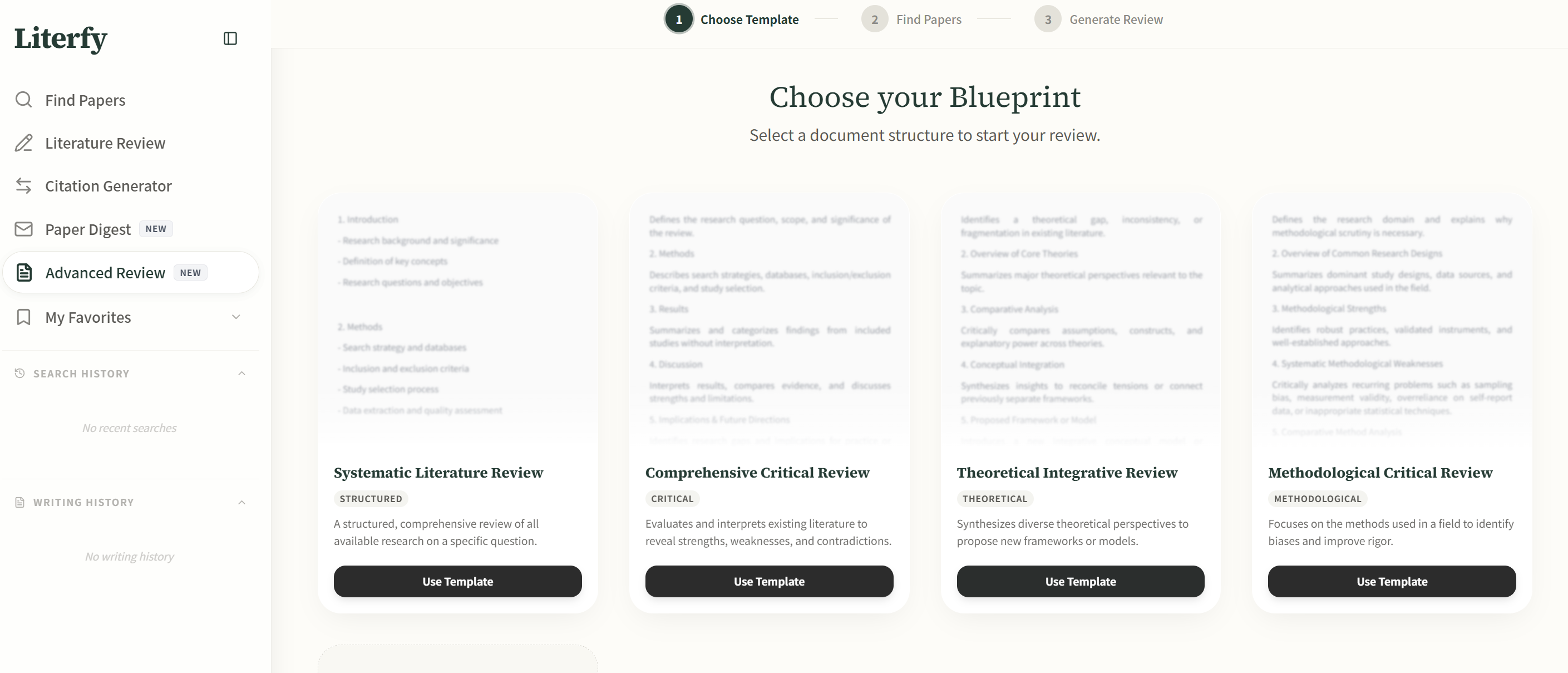
その価値は、レビューテキストの生成を支援するだけではありません。その価値は、プロセスにおける「論文第一」の側面、つまり、一般的なAIの自信からではなく、実際の論文から検索、候補リスト作成、整理、アウトライン作成、執筆をサポートすることにあります。
この区別は重要です。なぜなら、文献レビューは単なる執筆作業ではないからです。それはまず、ソース構造の作業なのです。
2番目のテスト:引用層は実際に信頼できますか?
2番目のテストは、多くの研究者が不注意になる場所から始まります。
文章が首尾一貫しているように見えると、引用層はすでに解決済みであるかのように扱われることがよくあります。
しかし、参考文献は見落としやすい方法で失敗することがあります。
- 存在しない参考文献:引用された論文が実際には存在しない。
- 不正確な参考文献:DOI、著者、年、ジャーナルが間違っている。
- 誤った主張:引用された論文が、実際に主張されていることを裏付けていない。
- 撤回された論文:引用された論文が撤回されている。
ここでCitelyが重要になります。
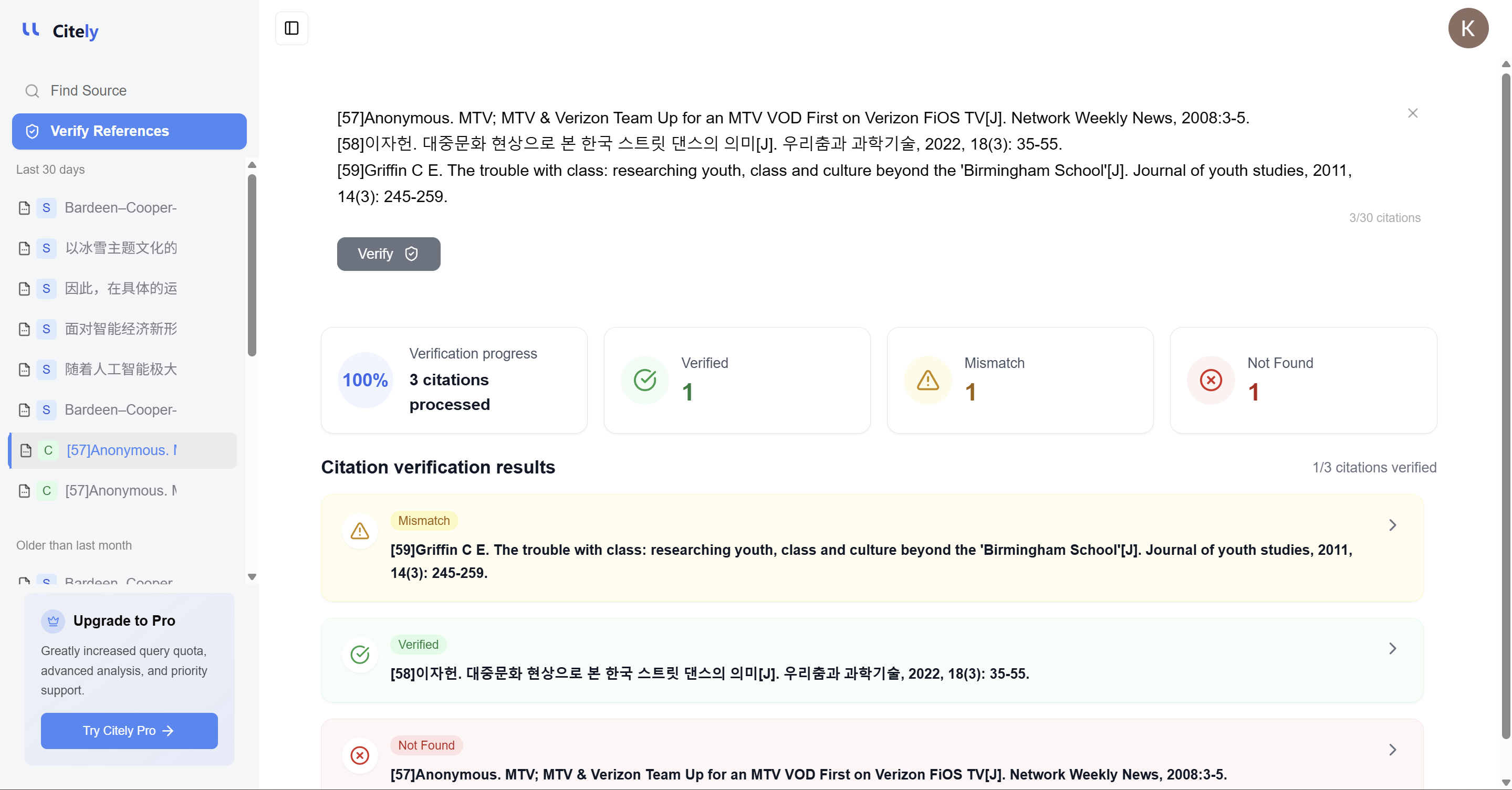
その役割は、参考文献リストをよりきれいに見せることではありません。その役割は、研究者が参考文献を検証し、元の情報源をたどり、引用がドラフトに残るに値するかどうかを判断するのを助けることです。
それは、レビューのドラフト作成とは全く異なる仕事です。
弱点:AI支援研究ワークフローが失敗する3つの場所
最も弱いAI支援研究ワークフローは、通常、次の3つの場所のいずれかで破綻します。
1. 論文セットが薄すぎるか、ノイズが多すぎる
ワークフローは論文を素早く取得しますが、選択的ではありません。
結果の山は得られますが、防御可能なレビュー基盤は得られません。ドラフトは情報に基づいているように聞こえますが、基礎となる文献のカバー範囲が薄すぎるか、ノイズが多すぎます。
2. アウトラインが不安定な論文セットに基づいている
アウトラインは早く現れ、生産的だと感じられます。
しかし、論文セットがまだ不安定な場合、その構造は学術的な形式をまとった単なる推測にすぎません。
3. 引用が未検証である
これは最も危険な失敗です。
著者、タイトル、掲載誌、DOIを含む引用は完成しているように見えます。ドラフトがきれいだと感じるので、研究者は次に進みます。しかし、誰かがその記録を適切に検証しない限り、ドラフトは洗練された言葉の裏に弱い証拠を隠している可能性があります。
解決策:2つの層を分離する
研究プロセス全体をシームレスに感じさせるために1つのツールに頼むよりも、ワークフローの各部分が適切な種類のコントロールを持っているかどうかを問う方が有用です。
それは通常、2つの層を分離することを意味します。
1. 論文セット層
この層は次のことに関するものです。
- 関連する論文の特定:ノイズを減らし、本当に重要なものに焦点を当てます。
- 論文の評価:各論文の強みと弱みを理解します。
- 論文の整理:主要なテーマ、議論、ギャップを特定します。
- レビューの構築:論文セットから直接、説得力のある物語を作成します。
2. 引用検証層
この層は次のことに関するものです。
- 参考文献の検証:引用された論文が実際に存在し、正確であることを確認します。
- 元の情報源の追跡:主張が元の情報源によって裏付けられていることを確認します。
- 撤回された論文の特定:引用された論文が撤回されていないことを確認します。
- 引用の信頼性の判断:引用がドラフトに残るに値するかどうかを決定します。
これらの2つの層が、同じタスクであると見せかけることなく互いにサポートし合うとき、ワークフローはより強固になります。
結論:スピードは十分ではない
低リスクの執筆では、スピードで十分な場合があります。
学術研究では、そうではありません。
あなたは次のようなものを書いているかもしれません。
- 査読付きジャーナル記事
- 博士論文
- 助成金申請書
- 政策提言書
- 教科書
これらのすべての場合において、誤った信頼性のコストは高くなります。
質の低い論文セットは、質の低い合成を生み出します。
未検証の引用層は、文章が強力に聞こえても、議論を弱めます。
そのため、最高のAI支援ワークフローは、目に見えるステップが最も少ないものではめったにありません。それは、最も明確なチェックポイントを持つものです。
研究のスピードは有用です。
研究の信頼性はより困難です。
両方を望むなら、答えはワークフロー全体を1つのAIインタラクションに平坦化することではありません。より良い答えは、適切なコントロールポイントに適切なツールを使用することです。
- 論文第一のワークフローを使用して、実際の情報源からレビューを構築します。
- 検証ワークフローを使用して、引用層が実際に信頼できることを確認します。
そうすることで、スピードは危険ではなく、有用なものになります。
関連記事
気になるテーマを深掘りしていきましょう。
研究ワークフロー全体を1つのAIツールに任せるべきではない理由
多くの研究者は、論文検索、分野の要約、文献レビューの生成、引用の提案、参考文献の検証を1つのAIツールに期待しています。この期待は便利ですが、通常は脆弱なワークフローと過信につながります。
続きを読むAIを活用して研究論文の一次情報を見つける方法 (2026年版)
2026年、AIを活用して研究論文の一次情報を見つける方法。AIは、学術研究における一次情報の発見と検証をどのように変革するのか。
続きを読む研究論文の学術文献を見つける方法(2026年版ガイド)
参考文献リストを一から作成していますか?このガイドでは、どこで検索するか、見つけたものをどう評価するか、そして提出前の最終確認まで、文献が本物であるかを確認する方法を網羅しています。
続きを読む追跡できない引用は証拠にならない
引用は正しく書式設定されていても、最も重要なテストである追跡可能性に失敗することがあります。読者がそれを実際のオリジナルソースにたどることができない場合、それは証拠として機能していません。AI支援の研究ワークフローでは、もっとこの問題が重要になります。
続きを読む引用は情報源ではない
多くの研究者は、引用文字列を確認しただけで情報源を検証したと考えています。これは重大な間違いです。引用は完全で一貫性があり、学術的に見えても、誤った論文、混同された記録、または元の情報源を指していない場合があります。
続きを読む最も危険な研究ドラフトは、完成しているように見えるもの
最も弱い学術ドラフトは、必ずしも乱雑に聞こえるものではありません。多くの場合、証拠の層が適切に構築され、チェックされる前に洗練されているように聞こえるものです。AI支援の研究ワークフローでは、流暢さによって2つの失敗が隠されがちです。
続きを読む