가장 위험한 인용 오류는 진짜처럼 보이는 것입니다.
최악의 인용 오류는 명백한 것이 아닙니다. 완전해 보이고, 학술적으로 들리며, 대충 훑어봐도 통과하지만, 실제로는 잘못된 출처, 혼합된 출처, 또는 아예 존재하지 않는 출처를 가리키는 참고문헌입니다. AI 기반 연구 워크플로우에서 이러한 오류는 가장 중요합니다.

가장 위험한 인용 오류는 쉼표 하나가 빠지거나 스타일 형식이 틀린 것이 아닙니다.
그것은 신뢰해서는 안 될 때 충분히 진짜처럼 보이는 인용입니다.
이것이 바로 살아남는 오류의 종류입니다.
연구자들은 보통 명백한 실수를 잡아냅니다. 깨진 제목, 누락된 연도, 눈에 띄게 불완전한 참고문헌. 이런 것들은 짜증 나지만, 스스로 드러나기 때문에 고치기도 더 쉽습니다.
더 어려운 문제는 신뢰할 수 있게 보이는 인용입니다.
저자 이름이 있습니다. 제목이 있습니다. 저널이 있습니다. 심지어 DOI도 있을 수 있습니다. 겉으로는 평범한 학술 참고문헌처럼 보입니다. 하지만 그 밑에는 뭔가 이상한 점이 있습니다. 세부 사항들이 서로 맞지 않습니다. DOI가 다른 논문으로 연결됩니다. 제목이 왜곡되었습니다. 또는 출처를 전혀 깔끔하게 추적할 수 없습니다.
이것이 바로 걱정해야 할 오류입니다.
왜 이런 오류가 그렇게 위험한가요?
답은 간단합니다. 저항 없이 워크플로우를 통과하기 때문입니다.
인용이 깔끔하게 보이면 사람들은 더 이상 의문을 제기하지 않습니다. 노트에 복사되고, 참고문헌 관리자에 저장되고, 원고에 삽입되며, 결국 참고문헌 목록으로 형식화됩니다. 모든 단계에서 약간의 권위를 더 얻습니다.
누군가 그것을 면밀히 확인할 때쯤이면 문제는 더 이상 국지적이지 않습니다. 이미 퍼져나갔습니다.
이것이 바로 이러한 종류의 인용 오류가 눈에 띄게 나쁜 오류보다 더 비싼 이유입니다. 나중에 시간을 낭비하고, 신뢰성을 더 조용히 약화시키며, 최종 결과물까지 살아남을 가능성이 훨씬 높습니다.
어디서 이런 오류가 발생하나요?
이러한 오류는 보통 네 가지 출처에서 발생합니다.
AI 생성 참고문헌
이것은 현재 가장 명백한 출처입니다.
AI 도구는 그럴듯해 보이는 참고문헌을 생성하는 데 매우 능숙합니다. 이것이 바로 AI 도구를 위험하게 만드는 이유입니다. 인용이 완전하게 느껴질 수 있지만, 실제로는 기본 출처가 잘못되었거나, 혼합되었거나, 아예 만들어진 것일 수 있습니다.
2차 복사
인용이 원본 출처 기록에서가 아니라 블로그, 토론 페이지, 다른 참고문헌 목록 또는 요약 도구에서 복사됩니다.
일단 이런 일이 발생하면 오류는 쉽게 퍼져나갑니다.
메타데이터 불일치
때로는 출처가 존재하지만, 제목, 저자, 연도, 출판 장소 및 DOI가 실제로는 동일한 논문에 속하지 않는 경우가 있습니다.
이것은 각 부분이 개별적으로 합리적으로 보일 수 있기 때문에 알아차리기 가장 어려운 오류 중 하나입니다.
워크플로우의 성급함
인용이 확인되기 전에 저장됩니다.
이것은 보통 워크플로우가 출처의 신뢰성보다는 작성 속도에 최적화되어 있을 때 발생합니다.
형식화는 진실을 보장하지 않습니다.
이것은 많은 사람들이 여전히 잘못 이해하고 있는 부분입니다.
형식화는 일관성을 향상시킬 수 있지만, 진실성을 향상시키지는 않습니다.
가짜 또는 불일치하는 인용도 APA, MLA, Chicago 또는 다른 어떤 스타일로도 완벽하게 형식화될 수 있습니다. 깔끔하게 보일 수 있지만, 가장 중요한 한 가지 테스트, 즉 실제 원본 출처로 추적될 수 있는지 여부에는 실패할 수 있습니다.
이것이 바로 인용 형식화와 인용 검증이 결코 동일한 작업으로 취급되어서는 안 되는 이유입니다.
하나는 표현입니다.
다른 하나는 증거 관리입니다.
"이 인용이 올바르게 보이나?"라고 묻는 대신, 더 강력한 워크플로우는 다음과 같이 묻습니다.
- 이 인용이 실제 출처로 추적될 수 있는가?
- 이 출처가 내가 주장하는 내용을 뒷받침하는가?
이것이 훨씬 더 나은 기준입니다.
워크플로우를 표면적인 신뢰에서 출처 기반의 신뢰로 전환시킵니다.
그리고 학술 작업에서는 이러한 구별이 매우 중요합니다.
인용 오류를 잡는 방법
좋은 소식은 워크플로우의 올바른 지점에서 확인하면 이러한 오류를 잡아낼 수 있다는 것입니다.
올바른 순서는 다음과 같습니다.
첫째, 실제 학술 출처에서 제목을 검색합니다.
형식화부터 시작하지 마십시오. 검색부터 시작하십시오.
실제 학술 데이터베이스 및 출처 기록에서 제목을 확인하십시오.
둘째, 전체 메타데이터를 비교합니다.
저자가 일치합니까? 연도가 일치합니까? DOI가 동일한 논문으로 연결됩니까? 출판 장소가 실제 기록과 일치합니까?
셋째, 출처를 원본으로 추적합니다.
인용이 반복되는 다른 곳에서 멈추지 마십시오. 신뢰할 수 있는 원본 기록에 도달할 때만 멈추십시오.
넷째, 그 다음에야 작성 워크플로우로 이동합니다.
출처가 확인되면 노트, 라이브러리 및 초고로 안전하게 이동할 수 있습니다.
이 순서는 나머지 워크플로우를 훨씬 더 신뢰할 수 있게 만듭니다.
AI 시대의 인용 검증
연구자들이 아이디어 구상, 요약, 초고 작성에 AI를 더 많이 사용할수록 인용 계층은 더욱 취약해집니다.
그렇다고 AI가 쓸모없다는 의미는 아닙니다. 검증 단계가 더 엄격해져야 한다는 의미입니다.
이전 워크플로우에서는 일부 인용 문제가 수동적인 부주의에서 비롯되었습니다.
새로운 워크플로우에서는 그 중 많은 부분이 그럴듯한 자동화에서 비롯됩니다.
이것은 위험 프로필을 변화시킵니다. 우리는 더 이상 지저분한 참고문헌만 수정하는 것이 아닙니다. 우리는 점점 더 깔끔해 보이지만 증거적으로 약한 참고문헌을 다루고 있습니다.
이것은 더 심각한 문제입니다.
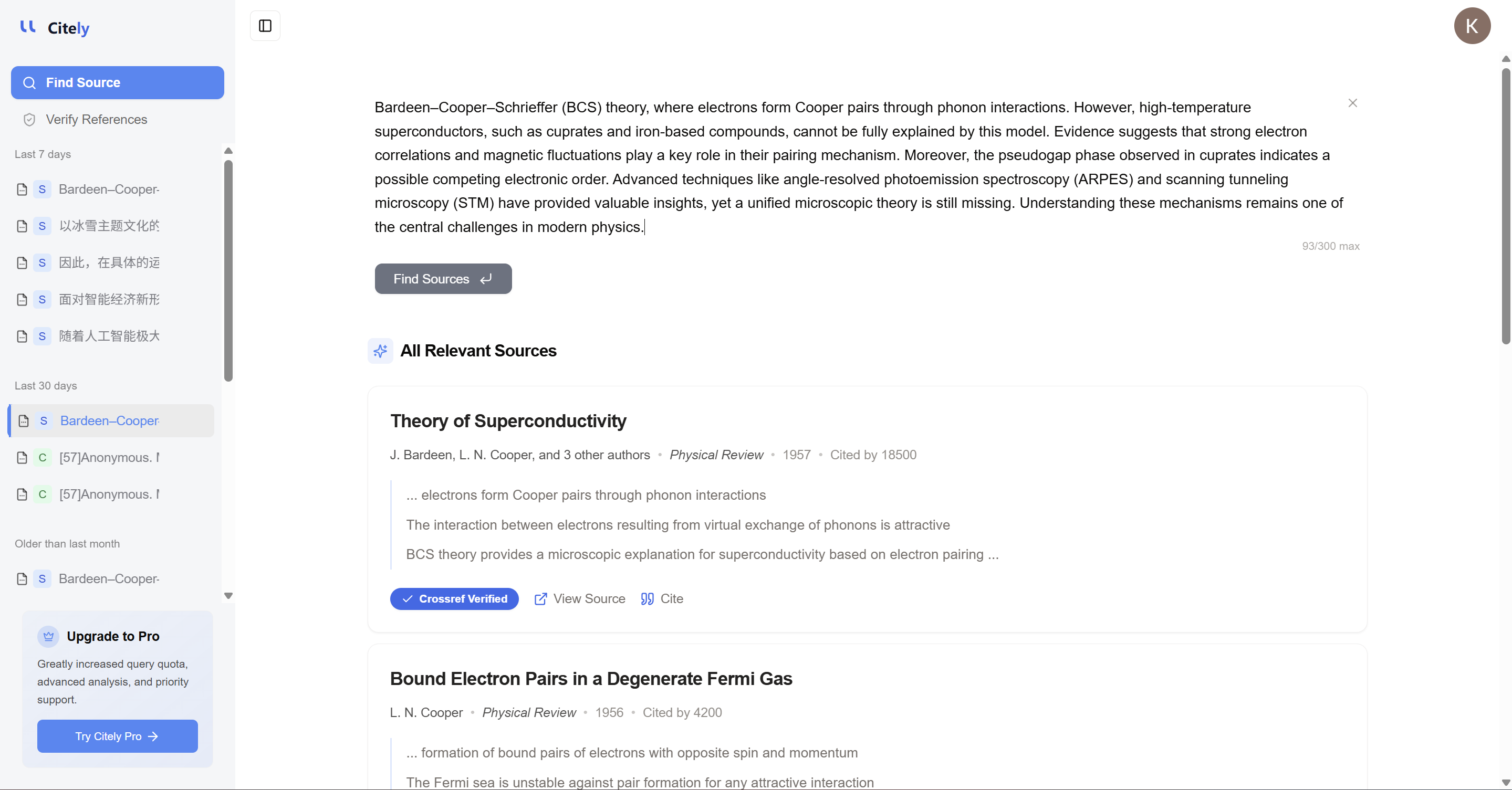
이것이 바로 Citely가 중요한 이유입니다.
필요한 것은 단순히 참고문헌을 관리하거나 형식을 정리하는 것이 아닙니다. 더 깊은 필요성은 인용이 진짜인지 확인하고, 원본 출처를 추적하며, 연구 워크플로우에 자리 잡기 전에 신뢰할 수 있게 보이는 종류의 참고문헌 오류를 잡아내는 것입니다.
이것이 출처를 정리하는 데 도움이 되는 인용 도구와 출처를 신뢰하는 데 도움이 되는 워크플로우의 차이입니다.
가장 큰 피해를 주는 인용 오류는 깨져 보이는 것이 아닙니다.
그것은 완성되어 보이는 것입니다.
참고문헌이 깔끔해 보인다고 해서 더 신뢰할 이유는 없습니다. 오히려 제대로 검증해야 할 이유입니다.
연구 글쓰기에서 가장 위험한 인용은 종종 검사를 피할 만큼 진짜처럼 보이는 것이기 때문입니다.
주요 내용
- 가장 위험한 인용 오류는 진짜처럼 보이는 것입니다. 명백한 오류는 쉽게 발견되지만, 그럴듯해 보이는 오류는 워크플로우를 통해 퍼져나가 최종 결과물까지 살아남을 수 있습니다.
- AI는 그럴듯해 보이는 가짜 인용을 생성할 수 있습니다. AI 도구는 그럴듯한 참고문헌을 생성하는 데 능숙하지만, 기본 출처가 잘못되었거나, 혼합되었거나, 아예 만들어진 것일 수 있습니다.
- 형식화는 진실을 보장하지 않습니다. 깔끔하게 형식화된 인용도 잘못된 출처를 가리킬 수 있습니다. 인용 형식화와 인용 검증은 별개의 작업입니다.
- 올바른 검증 순서가 중요합니다. 형식화 전에 실제 학술 출처에서 제목을 검색하고, 메타데이터를 비교하며, 원본 출처로 추적한 다음, 작성 워크플로우로 이동해야 합니다.
- AI 시대에는 더 엄격한 검증이 필요합니다. AI 기반 연구 워크플로우에서 인용 계층은 더 취약해지므로, 검증 단계는 더욱 중요하고 엄격해져야 합니다.
- Citely는 이 문제를 해결합니다. Citely는 인용이 진짜인지 확인하고, 원본 출처를 추적하며, 신뢰할 수 있게 보이는 오류를 잡아내어 연구자들이 출처를 신뢰할 수 있도록 돕습니다.
지금 Citely를 사용해 보세요!
인용 오류가 연구의 신뢰성을 훼손하게 두지 마세요. Citely를 사용하여 인용을 검증하고, 원본 출처를 찾고, 연구의 무결성을 보장하세요.
관련 글
관심 있는 주제를 계속 살펴보세요.
가장 위험한 연구 초고는 완성된 것처럼 보이는 초고입니다
가장 취약한 학술 초고는 항상 지저분하게 들리는 초고가 아닙니다. 종종 증거 계층이 제대로 구축되고 확인되기 전에 세련되게 들리는 초고입니다. AI 기반 연구 워크플로우에서 두 가지 실패는 유창함에 의해 종종 숨겨집니다.
더 읽기AI 생성 인용이 실제인지 확인하는 방법 (2026년 가이드)
2026년 AI 생성 인용을 검증하는 단계별 가이드. 가짜 참고문헌을 탐지하고, DOI를 확인하며, Citely와 같은 자동화 도구를 사용하여 2억 개 이상의 학술 기록을 몇 초 만에 교차 참조하는 방법을 알아보세요.
더 읽기텍스트에서 인용 출처 찾기: 단락 뒤에 숨겨진 원본 출처를 찾는 방법
Google Scholar, Crossref, 그리고 AI 기반 출처 찾기 워크플로우를 사용하여 문장, 단락 또는 연구 주장의 원본 출처를 찾는 방법을 알아보세요.
더 읽기AI 인용 검사기 비교: 2026년, 가짜 참고문헌을 실제로 잡아내는 도구는?
모든 인용 검사기가 같은 기능을 하는 것은 아닙니다. 어떤 것은 서식을 수정하고, 어떤 것은 표절을 확인합니다. 하지만 참고문헌이 실제로 존재하는지 확인하는 도구는 소수에 불과합니다. 각 유형의 도구가 무엇을 하고, 무엇을 하지 못하는지 알아보세요.
더 읽기인용 검증 101: CrossRef, DOI, 그리고 가짜 인용을 잡아내는 방법
CrossRef는 1억 5천만 개 이상의 학술 자료 메타데이터를 보유하고 있습니다. DOI가 어떻게 작동하는지, CrossRef 검증이 가짜 인용을 어떻게 잡아내는지, 그리고 이러한 시스템을 사용하여 참고문헌 목록을 정리하는 방법을 알아보세요.
더 읽기인용 검사기 vs 인용 생성기: 차이점은 무엇인가요?
인용 생성기는 서식이 지정된 참고 문헌을 만듭니다. 인용 검사기는 참고 문헌이 실제이고 정확한지 확인합니다. 각 도구가 실제로 하는 일과 언제 사용해야 하는지 알아보세요.
더 읽기